오늘은 C++에서의 쓰레드이다
지겹게 기억을 더듬어가면서 C기반의 포스팅을 했던 적이 있는데 C++에서도 지원을 한다니 새로웠다.
C기반 I/O Multithreading - 12. 멀티 프로세싱? 멀티 쓰레딩?
멀티 프로세싱에 이어서, 멀티 프로세싱의 단점이 보완되는 멀티 쓰레딩 개념이다. 사실 단점이 보완되기는 하는데 함께 딸려오는 문제 거리도 만만치 않기 때문에 좀 상세히 볼 필요가 있다ㅋ
typingdog.tistory.com
위 링크는 쓰레드
C++ 에서의 쓰레드
원래 쓰레드의 생성과 사용은 OS에 종속적이었고, API가 C 기반이었다. 하지만 C++ 11 표준에 쓰레드 라이브러리가 따로 들어가면서 OS에 독립적이고, 프로그래밍 언어 차원에서 지원이 된다.
임계 영역과 관련된 문제는 Mutex를 통해서 상호배제를 처리할 것인데 이 또한 C++ 프로그래밍 언어 차원에서 지원이 된다는 것이다. 그래서 C 기반의 코드를 그대로 C++ 코드로 변경하도록 해보겠다.
일단 간단하게 쓰레드 사용과 그에 동반하는 문제까지 설명하자면,

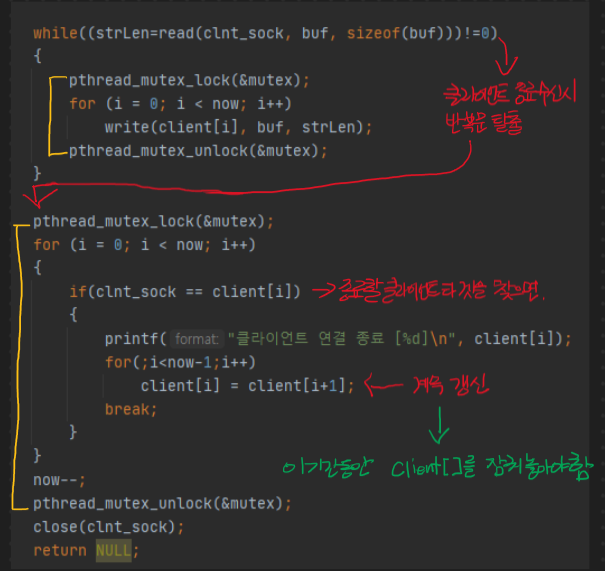
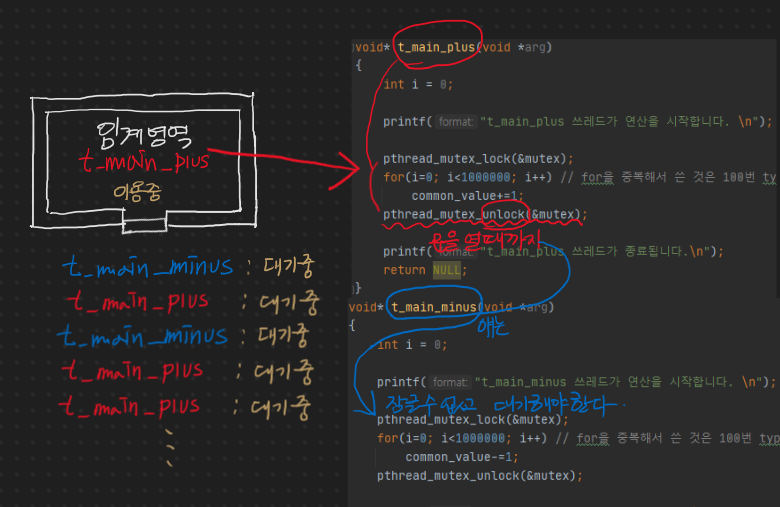
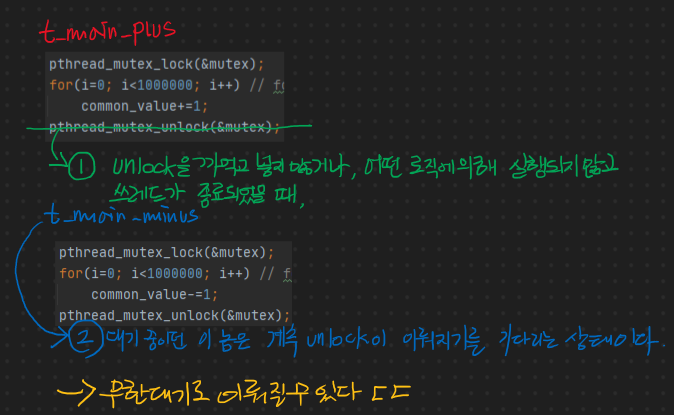
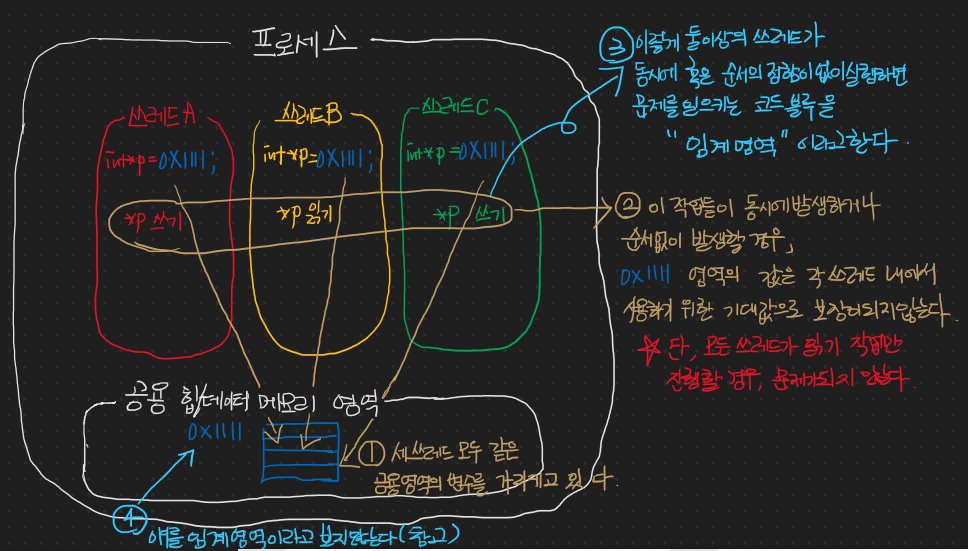
쓰레드에서 공통으로 접근할 수 있는 데이터 영역의 변수를 두 쓰레드에서 임계영역에서 사용이 되면서 기대하는 값과 다른 결과가 나오는 것에서부터 문제가 된다.

쓰레드 A에서는 동일한 횟수만큼 (1,000,000) 공용 Data 영역 변수를 1씩 증가시키고, 쓰레드 B에서는 동일한 횟수만큼 (1,000,000) 공용 Data 영역 변수를 1씩 감소시킨다.
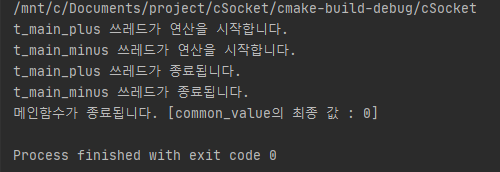
기대하는 값은 0 이겠지만(동일한 횟수만큼 1씩 증가시키고, 감소시켰기 때문) 쓰레드 동기화가 이루어지지 않은 탓에 0이 아닌 다른 값이 나온다.
문제에 대한 자세한 설명은 아래의 링크를 통해서 확인하면 된다.
C기반 I/O Multithreading - 14. 쓰레드의 치명적인 문제점
C기반 I/O MultiThreading - 12. 멀티 프로세싱? 멀티 쓰레딩? 멀티 프로세싱에 이어서, 멀티 프로세싱의 단점이 보완되는 멀티 쓰레딩 개념이다. 사실 단점이 보완되기는 하는데 함께 딸려오는 문제 거
typingdog.tistory.com
C언어 기반 쓰레드 구현(Mutex)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
|
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <pthread.h>
pthread_mutex_t mutex;
int common_value = 0;
void* t_main_plus(void *arg);
void* t_main_minus(void *arg);
int main(void)
{
pthread_t tid1, tid2;
pthread_mutex_init(&mutex, NULL);
pthread_create(&tid1, NULL, t_main_plus, NULL); // 쓰레드 생성
pthread_create(&tid2, NULL, t_main_minus, NULL); // 쓰레드 생성
pthread_detach(tid1); // tid1 에 해당하는 쓰레드가 종료됨과 동시에 소멸.
pthread_detach(tid2); // tid2 에 해당하는 쓰레드가 종료됨과 동시에 소멸.
sleep(7); // 종료되지 않도록 대기.
pthread_mutex_destroy(&mutex);
printf("메인함수가 종료됩니다. [common_value의 최종 값 : %d]\n",common_value);
return 0;
}
void* t_main_plus(void *arg)
{
int i = 0;
printf("t_main_plus 쓰레드가 연산을 시작합니다. \n");
pthread_mutex_lock(&mutex);
for(i=0; i<1000000; i++) // for을 중복해서 쓴 것은 100번 type을 검사하는 것보단 났다고 생각.
common_value+=1;
pthread_mutex_unlock(&mutex);
printf("t_main_plus 쓰레드가 종료됩니다.\n");
return NULL;
}
void* t_main_minus(void *arg)
{
int i = 0;
printf("t_main_minus 쓰레드가 연산을 시작합니다. \n");
pthread_mutex_lock(&mutex);
for(i=0; i<1000000; i++) // for을 중복해서 쓴 것은 100번 type을 검사하는 것보단 났다고 생각.
common_value-=1;
pthread_mutex_unlock(&mutex);
printf("t_main_minus 쓰레드가 종료됩니다.\n");
return NULL;
}
|
cs |

C++언어 기반 쓰레드 구현(Mutex)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
#include <iostream>
#include <thread>
#include <mutex>
std::mutex mtx;
int comm_value = 0;
int main(void)
{
std::thread t1([]() { mtx.lock(); for (int i = 0; i < 1000000; i++) comm_value--; mtx.unlock(); });
std::thread t2([]() { mtx.lock(); for (int i = 0; i < 1000000; i++) comm_value++; mtx.unlock(); });
t1.join();
t2.join();
std::cout << "comm_value의 값은 : " << comm_value << std::endl;
return 0;
}
|
cs |

위의 코드가 아래의 코드로 변환되었다고 생각하면 된다. 너무 간단하게 몇 줄이면 끝났다ㅋㅋㅋㅋ
끝.
'프로그래밍응용 > Modern & STL' 카테고리의 다른 글
| RAII (Resource Acquisition Is Initialization) (3) | 2021.02.11 |
|---|---|
| 함수 포인터를 대체하는 std::function (0) | 2021.02.08 |
| Lambda Expression (0) | 2021.01.27 |
| R-Value, Copy Elision, 이동 생성자, RVO, NRVO (0) | 2021.01.26 |
| 자료형 추론 auto / 범위 기반 for (0) | 2021.01.21 |