C++의 새로운 형 변환
- 기존 C언어 스타일의 형 변환 연산자
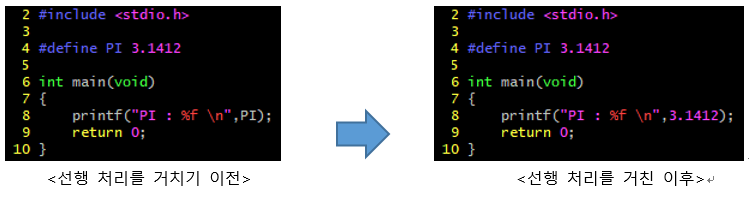
C언어 스타일의 형 변환 연산자( (자료형) 변수 및 상수 ) 형태는 C언어의 호환성을 위해서 C++에서도 제공을 한다. 그런데 문제는 C언어 스타일의 형 변환 연산자는 변환하지 못하는 대상이 없는 아주 강력한 연산자이다. 다음의 예제에서 이를 나타낸다.

39번 라인에서 Base 클래스 포인터 형을 Derived 클래스 포인터 형으로 형 변환하는 것은 일반적인 연산이 아니다. Derived 클래스 형이 필요했다면 애초에 Base 클래스 포인터 형으로 Derived 객체를 가리키게 생성할 필요가 없었다. 그리고 43번 라인은 확실하게 형 변환의 문제가 된다. 클래스 포인터 변수 pb2는 실재하지 않는 멤버를 호출한다. 왜냐하면 실제 생성된 객체는 A 클래스의 객체인데 B의 멤버 함수를 호출하기 때문이다. 이렇게 문제가 있음에도 불구하고 C 언어의 형 변환 연산자는 오류 하나 내주지 않는다.
C++ 언어에서는 이러한 문제를 보완한 4개의 연산자를 추가로 제공해준다.
static_cast / const_cast / dynamic_cast / reinterpret_cast
- dynamic_cast 연산자 : 상속 관계에서의 안전한 형 변환

<> 사이에 변환하고자 하는 객체의 포인터 또는 참조형으로 구성된 자료형의 이름을 둔다.
( ) 사이에 변환하고자 하는 대상의 이름을 둔다.
이 연산자를 통한 형 변환은 다음과 같은 형 변환 요구가 따라온다.
상속 관계에 놓여 있는 두 클래스 사이에 Derived 클래스의 포인터 및 참조형 데이터를 Base 클래스의 포인터 및 참조형 데이터로 형 변환하는 경우(Derived 클래스 포인터/참조형 -> base 클래스 포인터/참조형)
위의 요구에 부합하는 형 변환 이외의 변환이(형 변환의 방향이 반대인 경우) 해당 연산자를 통해 이루어지는 경우 컴파일러 차원의 에러가 발생한다. 아래는 그에 해당하는 예제와 실행 결과이다.


그러나 39행의 경우는 크게 문제가 되지 않고, 오히려 필요한 경우도 존재할 수 있는데 이러한 형 변환을 의도적으로 진행하는 것을 의도적으로 명시하기 위한 형 변환 연산자가 제공된다.
단, Derived 클래스 포인터/참조형 -> base 클래스 포인터/참조형으로 변환이 가능한 경우 또한 존재한다. 다음과 같은 가정 하에.
Base 클래스가 Polymorphic 클래스(하나 이상의 가상함수를 포함하는 클래스) 일 때!
상속 관계에 놓여 있는 두 클래스 사이에서 기초 클래스에 가상함수가 하나 이상 존재하면, dynamic_cast 연산자를 이용하여 Base 클래스 포인터/참조형 -> Derived 클래스 포인터/참조형으로의 변환이 가능하다! 다음은 클래스가 수정된 해당 예이다.


47번 라인은 원래 허용되지 않았던 연산이지만 가상 함수가 존재하는 이유로 허용되는 것을 볼 수 있다. 그러나 50번 라인은 pa2가 가리키는 대상을 pb2가 가리킬 수 없는 상황이다. 변환은 가능하지만 Segmentation fault 에러가 런타임에 나오는 것을 볼 수 있는데, 해당의 경우 반환하게 되면 NULL 값을 반환한다.

이렇게 dynamic_cast 형 변환 연산자는 안정적인 형 변환을 보장해주는데 컴파일 시간이 아닌 실행 시간에 안정성을 검사하도록 컴파일러가 바이너리 코드를 생성한다.
- static_cast 연산자 : A 타입에서 B 타입으로

위의 연산자는 dynamic_cast 연산자와 동일한 형태를 갖는다. static_cast 연산자는 Derived 클래스 포인터/참조형 -> base 클래스 포인터/참조형으로의 변경 뿐만 아니라, base 클래스 포인터/참조형 -> Derived 클래스 포인터/참조형으로의 변경 또한 허용한다. 그러나 그에 따른 책임은 프로그래머가 지도록 되어있다. 다음은 그 예이다.

두 변환 모두 허용은 하지만 특히, 43번과 같은 변환에 대한 결과는 예측할 수 없는 책임질 수 없는 결과가 나온다. static_cast는 프로그래머의 의도적인 변환임을, 그래서 책임 또한 지겠다는 의미가 내포되어 있다.
그리고 static_cast 연산자는 기본 자료형에 대해서도 형 변환이 가능하다.

그렇다면 static_cast 연산자는 그에 따른 결과는 연산 결과를 프로그래머가 책임지면 기존의 C 언어에서의 형 변환 연산자랑 무엇이 다를까?

기존 C 언어에서의 형 변환 연산자는 위와 같은 말도 안되는 경우를 허용한다. 그러나 static_cast로 형 변환을 진행하는 경우에는 다음과 같은 결과를 확인할 수 있다.

- const_cast 연산자 : const 성향을 삭제!

위의 연산자를 이용하여 const로 선언된 참조자 혹은 포인터의 const 성격을 제거하는 형 변환을 이룰 수 있다. 이와 같은 연산은 const의 가치를 떨어뜨릴 수 있지만 다음의 예와 같이 의미를 둘 수 있다.

함수의 인자 전달 시 const 선언으로 형의 불일치가 일어날 경우 요긴하게 쓰일 수 있는 연산자이다. 그러나 const에 대한 의미가 옅어지도록 하는 요소이므로 필요할 때만 사용한다. 그런데 const_cast 연산자로 변환된 형태에 대해서 값의 변경을 시도하면 런타임 에러가 발생하기는 한다.
- reinterpret_cast 연산자 : 상관없는 자료형으로의 형 변환

위와 같이 이전의 형 변환 연산자들과 동일한 형태를 띤다. reinterpret_cast 연산자는 전혀 상관없는 자료형으로의 형 변환을 행할 때 사용되는 연산자이다. 포인터를 대상으로 하는, 그리고 포인터와 관련이 있는 모든 유형의 형 변환을 허용한다.

위와 같은 형 변환 연산이 허용된다. 클래스 C와 클래스 D는 상속 관계가 아닌 전혀 다른 타입이기 때문이다.


위의 예제와 결과는 포인터를 대상으로 하는 포인터와 관련이 있는 모든 유형의 형 변환을 허용한다는 내용에 대한 예제인데 허용이 되지 않는 것 같다(보류)
- 형 변환 시 발생하는 예외

위와 같은 경우는 dynamic_cast 연산자의 두 번째 경우와 같은 경우인데(NULL 반환 경우), 참조자를 대상으로는 NULL 값을 반환할 수 없기 때문에 bad_cast 예외가 발생함을 참고한다.
'컴퓨터 언어 정리 > C++ 언어' 카테고리의 다른 글
| 24 예외 처리 (0) | 2020.10.15 |
|---|---|
| 23 템플릿 (0) | 2020.10.13 |
| 22 string 클래스 - 직접 일부 구현 (0) | 2020.10.12 |
| 21 연산자 오버로딩 (0) | 2020.09.23 |
| 20 다중 상속 (0) | 2020.09.22 |