문제를 해결하는데 앞서 문제를 작은 단위로 나누는 과정에서 그 작은 단위의 문제를 해결하는 하나 이상의 기능을 지닌 부 프로그램.
함수 정의의 기본 틀
‘ 함수_이름 ‘ 에는 말 그대로 함수의 이름을 정의한다.
‘ 출력_타입 ’ 에는 해당 함수가 값을 반환할 경우 반환하는 값의 자료형을 기재한다. -> 왜냐하면 함수의 값을 받을 때, 어떤 자료형 변수로 받을지 결정할 수 있어야 하기 때문이다.
‘ 입력_형태 ‘ 에는 함수가 실행될 때 입력 값으로 받는 인자를 기재한다. 여러 타입, 여러 개의 인자를 받을 수 있다.
‘ 함수의 내용 ‘ 에는 함수가 수행할 연산 명령들이 정의 된다.
‘ 출력_타입에_따른_반환_값 ‘ 에는 함수가 종료 하면서 반환하는 값을 기재하는데, 조건문에 의하여 여러 번 기재될 수 있으며 ‘ 출력_타입 ‘ 에 맞춰 값을 반환한다.
함수의 정의와 호출 및 선언
함수의 정의와 호출
<입력 X / 출력 X 인 func 함수의 정의와 호출>
<입력 O / 출력 X 인 func 함수의 정의와 호출>
<입력 X / 출력 O 인 func 함수의 정의와 호출>
<입력 O / 출력 O 인 func 함수의 정의와 호출>
함수의 선언
위와 같이 함수를 main 함수 밑에서 정의할 때, main 함수 내에서 함수의 호출이 정의보다 앞서는 이유로 함수가 존재 하지 않는다는 에러가 발생하는데 이 때 main 함수 상단의 선언을 통해서 정의가 밑에 있음을 컴파일러에게 명시하여 문제를 해결한다.
변수의 생명주기
<지역 변수( = 자동 변수 )>
중괄호 내에 일반적인 형태(자료형 + 이름)로 선언 되는 모든 변수
해당 지역(해당 변수를 감싼 가장 가까운 중괄호 내의 영역)에서만 유효
해당 지역을 벗어나면 자동으로 소멸
선언된 이름이 같아도 지역이 다르면 중복 선언이 가능
선언 시 메모리의 ‘스택’ 영역에 ‘쌓이는’ 형태로 할당 된다. (LIFO)
조건문 혹은 반복문 내에서 선언된 변수 그리고 함수에서의 매개 변수 또한 지역 변수이다.
지역 변수는 외부에서 선언된 동일한 이름의 변수를 가리게 된다. -> 변수의 이름을 통해 메모리에 접근 시 해당 지역에서 먼저 찾은 후 지역의 외부에서 찾는다.
for문이나 while문의 소괄호 내부가 아닌 중괄호 내에서 선언된 변수는 생성과 소멸을 반복한다. -> 반복은 중괄호의 진입과 탈출의 반복이기 때문
<전역 변수>
중괄호 내에 선언 되지 않는다.
프로그램의 시작과 동시에 메모리 공간에 할당되어 프로그램의 종료 시까지 존재한다.
초기화를 직접 하지 않더라도 0으로 자동 초기화 된다.
프로그램의 전체 영역 어디서든 접근이 가능하다.
<Static 정적 변수>
static 지역 변수
지역 변수에 static 키워드를 붙임으로써 생성되는 정적 변수. 선언된 중괄호 내에서만 접근이 가능( 지역 변수의 특성 ) 1회 초기화되고(직접 초기화 하지 않을 경우 0), 프로그램 종료 시까지 메모리 공간에 존재( 전역 변수의 특성 )
static 전역 변수
전역 변수에 static 키워드를 붙임으로써 생성되는 정적 변수. 정적 전역 변수는 파일 외부에서 extern 키워드를 이용한 접근이 불가능함. -> 변수의 접근 범위를 해당 파일로 변경
<Register 변수>
지역 변수에 register 키워드를 붙임으로써 생성되는 변수.
Register로 선언된 변수는 CPU 내에 존재하는 ‘레지스터’ 라는 메모리에 공간이 할당될 ‘확률’이 높다. 레지스터 영역은 작고, 중요한 영역으로 상당히 제한이 있는 메모리 공간이기 때문에 register 키워드를 붙인다고 해서 무조건적으로 레지스터 영역에 할당이 되는 것이 아니다. 컴파일러에게 요청을 하는 명령이다.
전역 변수에 register 키워드를 붙이는 요청은 컴파일러에 의해 거절 된다. 중요한 메모리 영역을 전역 변수로 계속 해서 할당을 시키는 것은 명백한 자원 낭비이기 때문이다.
재귀 함수
함수 내에서 자기 자신(함수)을 다시 호출하는 함수.
재귀 함수의 간단한 예이다. 재귀 함수의 필수 구성 요소는 다음과 같다.
빨간색에 해당하는 1번 원의 ‘ 재귀 호출 ‘ -> 자기 자신에서 자신을 다시 호출하는 것(복사본)
파란색에 해당하는 2번 원의 ‘ 탈출 조건 ‘ -> 재귀 구조의 무한 루프에 빠지지 않도록 한다.
참조자란 할당된 메모리 공간에 둘 이상의 이름을 부여하는 것으로 다시 말하면 참조자는 자신이 참조하는 변수를 대신할 수 있는 또 하나의 이름
다음은 참조자를 사용하는 예제이다.
10번 라인에서 & 연산자를 이용하여 참조자(레퍼런스)를 선언하고, 변수 num에 대해서 참조를 진행한다. 참조자 선언과 참조를 마친 후 13번 라인에서 일반 변수 num과 레퍼런스 ref의 주소를 출력해보았을 때 완전히 같은 주소를 출력하는 것을 확인할 수 있는 것으로 미루어 보아, 기존의 대상이 되는 변수에 이름만 부여되는 것임을 확인할 수 있다. 즉, 참조자는 이름을 하나 더 부여하는 별칭인 셈이다.
그리고 하나의 변수에 대해 여러 참조자를 선언하고 참조할 수 있으며, 참조자를 대상으로 참조자를 선언할 수 있다.
9번 라인부터 13번 라인까지 대상 변수에 대한 참조자의 수, 참조자를 대상으로 하는 거듭된 참조까지 가능함을 알 수 있다. 그리고 19번 라인에서 대상 변수 그리고 참조자들의 주소를 출력했을 때 모두 대상 변수의 주소로 같게 나왔음을 확인할 수 있다.
참조자의 잘못된 선언 형태에 대한 간단한 예제이다.
먼저, 10번 라인에서는 참조자를 선언만 하고, 참조를 하지 않은 상태인데 참조자는 선언과 동시에 어떤 대상을 꼭 참조해야만 한다. 그리고 11번 라인에서는 선언과 동시에 참조를 진행했지만 참조의 대상은 참조자의 타입이 맞는 변수가 대상이어야 한다. 마지막 12번 라인에서는 NULL로 선언과 동시에 참조를 하고 있지만 역시 마찬가지로 변수가 대상이 아니기 때문에 참조가 불가능하다. 이와 더불어 한 번 참조가 된 이후에는 참조의 대상 변경이 불가능하다.
참조의 가능 범위는 다음과 같이 크게 3가지가 존재한다.
일반 변수
배열 요소
포인터 변수
참조자와 함수
Call-By-Address와 Call-By-Reference 모두 주소 값을 인자로 전달하는 형태의 함수 호출은 뜻하는데, 그 사실 보다는 주소 값을 전달하되, 해당 주소를 이용하여 참조 혹은 값의 변경이 일어났는가를 볼 수 있어야 함. (결국, call-by-address와 call-by-reference 방법은 서로 비슷한 방법이라고 보일 수 있지만 전자는 단지 주소만을 전달하느냐 후자는 주소를 전달하고 참조를 행하느냐를 보는 것인데 전자의 경우는 주소만 전달될 뿐 참조가 일어나지 않기 때문에 call-by-value로 볼 수도 있음 그렇기 때문에 두 용어는 구분이 필요함을 이야기함.)
다음은 참조자를 이용한 swap 함수의 구현이다.
Const 참조자
참조자를 이용하여 call-by-reference를 구현할 때, 매개 변수에 참조자를 const화 시켜서 넣게 되면 해당 참조자 매개 변수를 이용하여 값의 변경을 허용하지 않겠다 라는 의미를 갖는다.
이러한 의미가 왜 필요한가?
위와 같은 예제를 마주쳤을 때, C언어에서는 num의 값이 바뀌지 않는 call-by-value 방식의 호출이라는 것을 위 예제만 보고도 알 수 있으나, C++언어에서는 참조자의 개념 때문에 call-by-reference인지 call-by-value인지 알 수가 없다. 이를 확인하기 위해서는 함수의 원형을 확인해야 하고 뿐만 아니라 정의까지 확인해야한다. (왜냐하면 참조자로 매개 변수를 선언했을지라도 참조 후 값의 변경이 있는지 없는지는 정의를 확인해야하기 때문이다.) 이러한 불편함을 해소하기 위해서 함수의 원형 선언만 보더라도 const 키워드로 인해 값의 변경이 일어나는지 일어나지 않는지를 확인할 수 있게 해준다. 다음과 같이.
그리고 const 참조자에는 이러한 경우도 있는데,
16번 라인에서 const를 이용한 변수의 상수화로 심볼릭 상수를 선언하였고, 17번 라인에서 ref 참조자로 심볼릭 상수와 참조 관계를 형성한다. 그리고 18번 라인에서 참조자를 통한 값의 변경을 행한다. 기껏 16번 라인에서 상수로 만들었는데 참조자를 통한 값을 변경을 하고 있다. 그러나 이는 허용하지 않는다. 17번 라인 참조 관계를 형성하는 부분에서부터 허용을 하지 않는다 왜냐하면?
C언어 정리에서 언급했듯이 대입 연산자를 기준으로 l-value 와 r-value의 자료형은 완벽하게 같아야 대입이 이루어지는데 현재 17번 라인에서는 l-value의 타입은 int& 이고, r-value의 타입은 const int 이다. 이는 다른 타입이기 때문에 대입에서 오류가 나는 것임.
그래서 위와 같이 맞춰 주어야만 오류가 나지 않는다.
또 const 참조자는 상수를 참조할 수 있는 특징을 가지고 있다.일반 참조자와 다르게 const 참조자를 이용해서상수와 참조 관계를 형성하려고 하면 상수가 해당 라인이 넘어가면 소멸되는 리터럴 상수가 아닌 임시 변수 형태로 생성되어 그 값을 가지고 있는 형태로 생성된다. 그렇기 때문에 그 임시 변수 공간과 참조 관계를 형성할 수 있는 것이다.
15번 라인에서 50이라는 임시 변수를 생성하고 그 임시 변수의 공간에 ref 이름을 부여한다. 7번 라인과 16번 라인 또한 같은 맥락이다.
함수의 출력 타입이 참조형인 경우
위와 같은 함수 정의에서 14번 라인의 경우에는 arg 변수에 대한 새로운 참조 관계가 형성되는 경우이고, 15번 라인에서는 200이라고 하는 값이 반환된 것이고 v에는 값이 저장되는 경우이다.
위와 같은 경우에는 반환 값을 참조가 아닌 일반 자료형으로 지정한 경우인데 이 경우 반환되는 값은 단순히 값만 반환되기 때문에 일반 변수로 값을 리턴 값을 받을 수 있지만, 25번 라인처럼 참조 관계를 형성할 수는 없다 왜냐하면 int& r = 200; 형태와 같은 형태이기 때문이다.
위와 같이 함수 내의 지역 특성을 지니는 지역 변수에 대해서 참조 관계를 형성시켜서는 안된다(왼쪽). 이는 포인터로 지역 변수에 대해서 가리키고 참조하는 것과 다를 것이 없다.(오른쪽). 함수가 종료되면 사라지는 지역적 특성을 지니는 지역 변수를 함수의 외부(함수 종료 상태의 지역)에서 참조한다는 것은 이미 해체되어 없는 공간 혹은 다른 쓰레드 작업에 의해 이미 다른 중요 값으로 채워져 있는 공간을 참조하고 조작할 수 있는 가능성이 있기 때문에 잘못된 것.
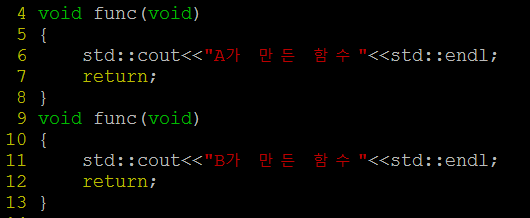
위와 같은 예제에서는 두 함수 모두 수행하는 내용은 다르지만 이름, 매개 변수가 같다는 이유로 오버로딩이 적용되지 않고 에러가 난다. 예제에서는 나타나지 않지만 두 함수 모두 다른 모듈이나 소스에 이미 의존되어 있는 부분이 있기 때문에 이름을 바꾸거나 할 수 없다. 이러한 경우 이름 공간을 이용한다.
위의 예제에서는 각 함수를 A, B라는 이름 공간(namespace) 으로 감싸고, 영역을 구분하였다. 영역을 구분하였기 때문에 함수 중복 문제로 오류가 발생하지 않는다. 그리고 24, 25번 라인에서는 ‘ :: ’ 범위 지정 연산자를 이용하여 이름 공간을 지정하여 그 내부의 함수를 지정하여 호출하는 식으로 함수 호출을 진행함.
이름 공간 기반의 함수 선언과 정의 구분
이름 공간에서 동일한 이름 공간 내의 함수 호출 및 변수 참조가 일어날 경우 범위 지정 연산자를 이용하여 이름 공간을 명시할 필요가 없다.
이름 공간의 중첩
이름 공간은 중첩이 가능하고, 범위 지정 연산자를 거듭 이용하여 범위를 지정하고 변수나 함수에 접근한다.
이름 공간 std
std::cout, std::cin, std::endl 등은 모두 이름 공간 내의 어떤 요소들이었다.
위와 같은 형태로 존재하고 있는 요소들이고, cout/cin/endl 은 추후에 정리.
using 연산자를 이용한 이름 공간의 명시
위와 같이 이름 공간 전체를 명시하여 이름 공간의 범위 지정 연산을 생략할 수 있다.
위와 같이 이름 공간 내의 특정 요소를 지정하여 이름 공간 범위 지정을 생략할 수 있다.
아래는 이름 공간을 명시 혹은 이름 공간 내의 특정 요소에 이름 공간을 명시하여 범위 지정 연산을 생략한 예를 보여준다.
왼쪽과 같은 형식으로 while문의 중괄호 속 내용을 반복하여 실행하는데 조건이 참인 경우에만 반복 내용을 실행하고, 조건이 거짓이 되는 순간을 꼭 만들어 주어야 한다. 즉, 탈출 조건을 만들어 주어야 하는데 그 탈출 조건은 소괄호 속 조건과 반복 카운터 변수의 증감을 통해 이룰 수 있다.
For문
역할은 while문과 완전히 같지만 형식이 주어져서 더욱 보기 깔끔하다 그러나 코딩의 유연성은 while문에 비해서 조금 떨어진다. for문의 동작 순서는 while문과 완전히 같다.
초기문 -> 조건문 -> 반복 내용 -> 증감문 -> 조건문 -> 반복 내용 -> 증감문 -> ~ -> 조건문 -> for문 종료
위와 같은 순으로 반복한다.
Do-While문
위와 같은 형식으로 반복을 진행하는데, 다른 반복문과 다른 특이한 점은 반복 내용을 한 번은 무조건 실행하는 경우에 사용한다. Do~While 문은 조건과 상관없이 딱 한 번은 무조건 실행하게 되어 있다. 왜냐하면 조건을 밑에서 검사하는 형식이므로.
분기
프로그램을 처음부터 끝까지 모두 실행하는 형태가 아닌 프로그램의 흐름을 원하는 형태로 제어하기 위한 구문.
If문
아주 간단하게 소괄호 내의 조건이 만족하면 (참이면) 반복 내용을 실행하고, 만족하지 못하면 중괄호 속에 해당하는 내용은 통째로 실행하지 않고 뛰어 넘는다.
다음과 같이 중괄호의 생략도 가능한데 이러한 경우는 반복할 문장이 한 줄일 때만 가능하다.
다음과 같이 else 를 이용하면 위의 if 조건을 만족하지 않은 모든 경우를 다 받아들이는 구문이 존재한다. 여기서 기억해야하는 중요한 포인트는 else는 위의 if 조건에 부합한 모든 경우들을 수용하기 때문에 따로 조건 검사를 하지 않는다는 것이다. 위와 같은 포인트를 잘 기억하고 다음을 보도록 하자.
다음과 같이 여러 조건을 if문으로 채우는 경우에는 모든 조건을 하나하나 검사하게 된다. 예를 들어 사칙 연산을 택하는 프로그램이 존재할 때 더하기, 빼기, 곱하기, 나누기의 총 네 개의 연산이 존재하지만 결국 선택되는 연산은 하나이다. 그러므로 한 가지 연산이 선택되었을 때에는 나머지 연산에 대해서는 확인하는 작업은 필요로 하지 않다. 다만, if문으로 제시되는 조건들이 모두 연관이 있는 하나의 주제에서의 선택에 대한 조건임을 전제로 한다.
왼쪽의 경우가 하나의 주제에 대해서 선택을 할 때, 모든 조건을 다 검사하는 소스이고, 오른쪽의 경우는 어떤 조건을 만족하게 될 경우 그 조건보다 아래에 오는 조건들은 자연스럽게 무시하는 경우의 소스이다. 이것이 가능한 이유는 위에서 언급한 두 가지 조건으로 인해 가능해진다.
실행할 문장이 한 줄일 경우에는 중괄호를 생략할 수 있다.
else는 위의 라인의 if 조건에 부합한 모든 경우들을 수용하기 때문에 따로 조건 검사를 하지 않는다
이 두 전제에 의해서 else if라는 문장이 생긴다.
원래 형태의 소스이고, 이 부분에서 두 가지 전제를 적용하여 중괄호를 없애게 되면 else if 구문을 확인할 수 있다. else 바로 밑의 조건문은 모두 유기적으로 연관되어 있기 때문에 if 문과 함께 한 줄로 취급하는 것이다. 그렇기 때문에 else의 중괄호를 생략할 수 있는 것이다.
결국, if, else if, else 구문은 if와 else 구문을 중첩시킨 형태에 지나지 않는다.
조건 연산자(삼항 연산자)
If 조건문을 대체할 수 있는 조건 연산자이다. 다음과 같은 형식을 지니고 ‘?’, ‘:’ 두 개의 연산자와 세 개의 피연산자를 이용하여 조건에 대한 결과 반환을 수행한다.
다음은 위와 따른 예제이다.
Switch~Case문
스위치~케이스문은 if문과 마찬가지로 분기를 통한 프로그램의 흐름을 제어해주는 방법 중 하나인데 if문과는 구조가 많이 다르고 조금은 제한적인 형태로 구성되어 있지만 간결하고 가독성이 좋아진다는 장점이 있다.
switch 키워드 옆 소괄호에는 분기 선택에 대한 정보가 담겨 있는 ‘정수형’ 변수가 인자로 전달되어야 한다. 그리고 그 전달된 값을 case 별로 나눈 것이 11번, 14번, 17번 라인이다. 여기서 짚어야 할 포인트는 분기의 조건으로 범위가 올 수 없고, 떨어지는 값의 형태로 분기가 일어난다는 것이다. 그리고 해당 case부터 break; 부분 사이의 실행 내용을 실행한다. break는 switch문 하나를 탈출하는 분기이며 반복문과는 관련이 없다. 만약 break를 생략하게 되면 전달되어온 인자의 값과는 상관없이 다음 case 영역의 break문 전까지 모조리 실행하게 된다. 그리고 마지막으로 default는 위에서 정의된 모든 case 분기에 빠지지 못한 경우는 모두 이 default 영역으로 분기된다. else와 같은 역할이라고 보면 된다.
goto문
레이블을 이용하여 분기를 제어하는 형태이다.
‘ 레이블: ’ 형식으로 레이블을 마킹한 후, ‘ goto 마킹한_레이블명; ‘ 명령어를 통해 프로그램의 흐름을 마킹한 레이블 라인으로 변경한다.
이 goto문은 절차지향의 패러다임에 위배되는데 그 이유는 위에서 아래로의 순차적인 실행이 아니라, 뒤죽박죽 어느 라인의 위치이든 간에 상관없이 흐름 변경이 가능하다. 즉, 프로그램의 자연스러운 흐름을 방해하기 때문이다.
Continue & Break문
먼저, continue문이다.
위와 같은 형식을 갖추며 continue를 감싸고 있는 가장 가까운 반복문의 조건 검사 위치로 이동한다. 단순히 반복문의 상단으로 프로그램의 흐름이 이동하는 것이 아니라, 조건을 찾아가는 것이다. 즉, do~while문에서는 위로 가는 것이 아닌 하단의 조건 위치로 프로그램의 흐름이 변경된다. 그리고 for문에서 continue문을 실행하게 될 경우에는 조건문을 실행하기 이전에 증감문 또한 실행한 뒤 조건문을 실행하러 상단으로 위치한다.
다음은 break문이다.
위와 같은 형식을 갖추며 break를 감싸고 있는 가장 가까운 반복문 하나를 탈출한다. 중첩된 반복문에서도 마찬가지로 break를 감싸고 있는 가장 가까운 반복문 ‘1개’만 탈출한다.
C++에서는 함수의 매개 변수에 다음과 같이 값을 대입하는 형태를 취함으로써 디폴트 값이라는 것을 설정할 수 있다. 디폴트 값이라 함은 기본적으로 설정되어 있는 값을 이야기한다.
매개 변수의 선언을 할 때, 값을 대입하는 형태로 선언되어 있는데 이는 다음과 같은 의미를 내포하고 있다.
함수 호출 시 인자를 전달하지 않으면 미리 대입된 값으로 전달된 것으로 간주하겠다.
그렇기 때문에 14번 라인에서 값이 전달되지 않더라도 함수의 정의, 선언 부분에 디폴트로 대입된 값으로 인자가 전달된 것으로 간주하고 함수 실행이 수행된 것이다.
디폴트 값은 함수의 선언 부분에만 표현
main 함수 윗 부분에 함수 정의 및 선언하는 경우
2. 함수의 정의와 선언을 분리하는 경우 -> 선언 부에 디폴트 값을 기재하고 정의에는 기재하지 않음.
부분적인 디폴트 값의 설정
위의 예처럼 매개 변수의 디폴트 값을 부분적으로 채울 수 있는데 중요한 것은 매개 변수의 오른쪽부터 왼쪽으로 차례대로 채워 나가는 형식으로 디폴트 값을 설정해야 한다는 것이다. 이렇게 행하는 이유는 함수에 전달되는 인자는 왼쪽에서 오른쪽으로 채워지기 때문.
함수 오버로딩과 디폴트 매개 변수의 모호성
위와 같은 예는 func라는 함수 이름으로 오버로딩이 적용되고 있으나 6번 라인에서의 디폴트 값 정의, 11번 라인의 인자를 받지 않는 void 형태의 인자 정의로 인해 19번 라인에서 오버로딩 된 func 함수 호출 시 어떤 함수를 호출해야 하는지 알 수 없는 애매한 상황이다. 가급적 이런 경우를 피해서 코딩
어느 정도의 크기를 저장할 것인지 적절한 크기를 결정 EX) (정수) 4바이트 정도, (문자열) 20바이트 길이 정도
예를 들어, 정수를 저장할 것이고, 크기는 4바이트 정도로 할께요 -> int
다음은 자료형의 저장 가능한 타입과 크기, 표현 범위를 나타낸 표이다.
이토록 다양한 자료형을 제공하는 이유는?
데이터의 표현 방식이 정수와 실수로 나뉘므로 최소 두 개의 종류가 보장되어야 한다.
메모리 공간의 효율적인 사용을 위해 같은 데이터 방식(정수 혹은 실수)이더라도, 다양한 크기로 제공되어야 한다.
sizeof 연산자를 이용한 자료형의 크기 확인
다른 자료형에도 마찬가지로 똑같이 적용되고, 10번 라인의 경우처럼 변수의 이름이 전달될 경우 해당 변수의 전체 크기를 계산한 결과를 반환한다. 즉, 배열의 경우 자료형 x 배열의 개수를 구하고, 반환한다는 의미.
정수 표현에서의 일반적인 자료형의 선택
short, char 형으로 선언한 변수를 이용하여 계산을 하였는데도 불구하고(10라인) 덧셈을 한 결과가(11라인) 1바이트, 2바이트가 아닌 4바이트 형태로 계산되었다.
-> CPU가 정수 연산을 할 때 가장 적합한 크기의 정수 자료형을 int 로 정의하였고, 그로 인해 다른 자료형의 연산 속도보다 같거나 빠르기 때문에 int 형 연산으로 변환하면서까지 연산을 진행한다.
-> 연산의 속도는 int형이 효율적이고 빠르지만, 데이터의 크기를 중요시하는 곳에서는 char, short를 사용하는 것이 중요하다.
실수 표현에서의 일반적인 자료형의 선택
실수에서 중요한 요소는 ‘정밀도’이다. 실수에서는 부동 소수점 오차가 발생하기 때문에 정확하게 값을 표현해낼 수 있는 소수점 이하의 자릿수가 존재하는데 이것이 바로 ‘정밀도’ 이다.
다음은 실수 자료형에서 정밀도를 나타내는 표이다.
실수 자료형에서는 double이 int와 같은 역할로 선택되어진다.
Double과 float 자료형 변수를 선언한 후, 값을 각각 입력 받고 출력하는 예제인데 float와 double 자료형의 출력 시 서식 문자는 같음을 알 수 있지만 입력 시 서식 문자는 다름을 확인할 수 있다.
문자의 표현 방식
문자를 표현할 때는 아스키(ASCII) 코드를 이용한다. 즉, 정수 값과 문자를 매칭하여 내부적으로는 정수로 연산하지만 이를 표현할 때에는 해당 정수 값에 맵핑 되어 있는 문자를 출력 및 표현을 한다.
8번 라인을 봤을 때 문자는 작은 따옴표( ‘ )로 감싸져 표현이 되고, 이 때 ch 변수에 값이 저장될 때에는 ‘a’라는 문자 형태의 값이 들어가는 것이 아니라 ‘a’의 아스키 코드 맵핑 값이 저장됨을 10번 라인을 통해 알 수 있다.
unsigned 0과 양의 정수 표현
- 정수 자료형의 이름 앞에만 unsigned를 붙일 수 있다.
- Unsigned 키워드가 붙을 시에는 부호 비트(MSB) 도 데이터를 표현하는데 사용이 된다. (부호가 사라짐)
- 표현할 수 있는 값이 0 이상의 범위로 두 배가 된다.
상수
상수는 이 자료형에 근거하여 선언되며, 리터럴(literal) 상수와 심볼릭(symbolic) 상수로 나뉘어진다. 자료형에 근거 되어 선언되는 이유는 CPU의 연산 대상이 되려면 메모리 상에 적재되어 CPU가 접근할 수 있는 주소를 할당 받아야 하기 때문이다. -> 모든 상수는 메모리에 할당된다.
먼저 이름을 지니지 않는 리터럴 상수이다.
위와 같은 예가 리터럴 상수의 예이다. 8번 라인에서는 10과 20이 int형, 10.1과 20.2는 double형으로 메모리에 적재된다.
앞서 일반적으로 연산 효율이 좋고, 넓은 정밀도로 인해 선택되어 지는 int형과 double형으로 상수의 자료형이 될 수 있고 자료형이 결정되는 요인은 대입 연산자 왼편의 자료형에 따른 것이 아니라 상수 자체의 종류에 따라서 결정되는 것이다.
두 자료형 이외의 값을 이용하여 자료형을 할당하기 위해서는 형 변환 혹은 접미사를 이용한다. 다음은 접미사를 활용하여 상수 자료형을 할당하는 예이다.
다음은 이름을 지니는 심볼릭 상수이다.
심볼릭 상수는 이름이 존재하는 상수이기 때문에 상수가 존재하는 해당 라인을 넘기더라도, 재 사용이 가능하며 이름을 활용하여 대입 연산자를 통해서 값의 변경을 방지하여 값을 변경하면 에러가 발생하도록 하는 특징을 지니고 있다.
심볼릭 상수 선언의 첫 번째 방법은 const 키워드를 이용한 변수의 상수화다.
위와 같이 const 키워드를 이용하여 변수를 상수화 하게 될 경우에는 선언과 동시에 초기화를 해야 하고, 이름을 통한(혹은 그 외의 어떤 방법으로도) 값의 변경은 금지된다.
두 번째 방법은 매크로를 이용한 방법이다.
자료형의 변환
자료형에서 가장 중요한 것은 모든 연산은 완벽하게 같은 자료형끼리 연산이 가능하다는 점이다.특히 대입 연산 시에도 대입 연산자를 기준으로 왼편(l-value)과 오른편(r-value)의 형(type)이 일치해야 한다. 다른 연산자의 경우에도 마찬가지이다. 자료형이 다름에도 불구하고 오류 없이 연산이 가능한 이유는 자료형의 형 변환(자동, 묵시적)이 이루어졌기 때문이다.
자동 형 변환(묵시적 형 변환)
먼저, 대입 연산 시 값을 전달하는 과정에서 자동으로 발생하는 형의 변환이 존재한다.
10번 라인에서 실수형 변수에 정수형 값을 넣었고, 11번 라인에서 정수형 변수에 실수형 값을 넣었다. 다음은 이에 대한 출력 결과이다.
결과에서 알 수 있듯이 11번 라인에서의 대입은 0.14에 해당하는 값이 모두 손실되었다. 정수형 자료형은 실수를 표현할 수 없기 때문이다. 또한, 바이트 크기가 큰 변수를 바이트 크기가 작은 변수로 형 변환하는 경우에는 상위 바이트의 손실로 인해 부호가 변경되거나, 값이 훼손될 수 있다.
다음은 정수의 승격에 의한 자동 형 변환이다. 정수형 연산에서 일반적인 자료형의 선택 시 int형으로 변환되어 연산이 진행되기 때문에 short나 char 등의 자료형으로 연산을 진행하더라도 int 형으로 변환 되어 연산이 진행된 후 다시 원래 자료형으로 다시 변환이 이루어 진다.
다음은 연산 시 피연산자의 자료형 불일치로 발생하는 자동 형 변환이다.
이와 같은 경우에서 double <- int + double의 형태인데 연산을 진행함에 있어서 두 피연산자의 자료형이 서로 다를 때에는 자료형을 통일시켜주어야 하는데 이 경우에 강제적으로 형 변환을 하지 않는 이상 피연산자의 자동 형 변환이 발생한다. 이 때, 어느 자료형을 어떤 자료형으로 변환시켜줄 것인지를 정해야 한다. 변환할 자료형, 변환될 자료형의 선택은 다음과 같은 규칙으로 진행하면 된다.
데이터의 손실을 최소화하는 방향으로 자료형을 선택
int형과 double형이 피연산자로 오는 경우에는 int형을 double형으로 변경하는 것이 데이터의 손실이 최소화하는 방향이다.
그리고 다음은 최소화하는 방향의 우선 순위를 나타낸 것이다.
우선 순위의 기준은 단순히 바이트 크기가 아니라, 정수와 실수 즉 ‘소수부의 손실’을 고려한 순위 기준이다. long long형과 float형을 보면 알 수 있다.
강제 형 변환(명시적 형 변환)
명시적인 형 변환은 형 변환 연산자를 이용하여 강제로 자료형을 변환하는 방법이다.
위와 같은 예에서 num1과 num2의 자료형은 서로 같기 때문에 정수형으로써 나눗셈이 진행되므로 결과 값은 0이 되고 대입 시 일어나는 자동 형 변환으로 인해 실수형 0이 num에 저장된다. 이러한 경우에 강제 형 변환을 이용하게 되면 다음과 같다.
위와 같이 num1을 강제로 double형으로 형 변환시키면 피연산자 불일치와 연산자 변환 우선 순위에 의거하여 num2 또한 double형으로 자동 형 변환이 이루어져 실수 연산이 이루어지고 그 값이 그대로 num으로 대입된다.
C 언어에서는 두 함수를 정의하고 선언하는데 함수의 이름이 같으면 아무리 함수의 내용이 다르다고 하더라도 허용하지 않았다. 위의 예제에서 sum을 호출할 때, 어떤 함수의 정의를 타겟으로 호출했는지 알 수 있다. 이렇게 호출되는 함수 명은 같지만 어떤 함수 정의를 타겟으로 하였는지 알 수 있었던 이유는 함수 호출의 인자와 함수 선언의 매개 변수 정보를 통해서 호출하고자 하는 함수를 구분할 수 있다.
즉, 함수 호출 시 전달되는 인자를 통해 호출되고자 하는 함수의 구분이 가능하기 때문에 C++에서는 함수의 정의에서 매개 변수의 선언 형태가 다르다면 동일한 이름의 함수 정의를 허용할 수 있다. 이를 함수 오버로딩이라 한다.
함수 오버로딩 시 필요한 정보 :함수 이름 + 함수의 매개변수 + const 여부
함수의 이름은 같아야 함수 오버로딩이 적용되고, 함수의 매개변수의 경우 매개 변수들의 타입 혹은 개수 정보가 달라야 오버로딩이 가능하다. 그리고 const 여부의 경우는 추후 내용 기록한다. 중요한 것은 반환 타입은 오버로딩에 필요한 정보가 아니므로 반환 타입이 다르다고 해서 오버로딩이 적용되지 않는다.
개정 C언어와 C++에서는 참과 거짓의 표현을 위한 키워드 true와 false를 정의 하고 있다. 이러한 true와 false 는 단순 1과 0의 값이 아니라, 그 자체로 의미 있는 데이터이기 때문에 이런 유형의 데이터를 저장하기 위한 자료형이 존재한다. true와 false 데이터는 bool형 데이터라고 하고, 이러한 bool형 데이터를 지원하는 기본 자료형 bool이 존재한다.
다음은 bool 자료형을 이용한 예제를 나타낸 소스이다.
사용자로부터 입력 받는 number 변수에 10이 들어가면 true 값을, 그 외의 값이 들어가면 false 값을 반환 한다.