C기반 I/O Multithreading - 12. 멀티 프로세싱? 멀티 쓰레딩?
멀티 프로세싱에 이어서, 멀티 프로세싱의 단점이 보완되는 멀티 쓰레딩 개념이다. 사실 단점이 보완되기는 하는데 함께 딸려오는 문제 거리도 만만치 않기 때문에 좀 상세히 볼 필요가 있다ㅋ
typingdog.tistory.com
C기반 I/O Multithreading - 13. 쓰레드의 생성과 소멸까지
C기반 I/O MultiThreading - 12. 멀티 프로세싱? 멀티 쓰레딩? 멀티 프로세싱에 이어서, 멀티 프로세싱의 단점이 보완되는 멀티 쓰레딩 개념이다. 사실 단점이 보완되기는 하는데 함께 딸려오는 문제 거
typingdog.tistory.com
C기반 I/O Multithreading - 14. 쓰레드의 치명적인 문제점
C기반 I/O MultiThreading - 12. 멀티 프로세싱? 멀티 쓰레딩? 멀티 프로세싱에 이어서, 멀티 프로세싱의 단점이 보완되는 멀티 쓰레딩 개념이다. 사실 단점이 보완되기는 하는데 함께 딸려오는 문제 거
typingdog.tistory.com
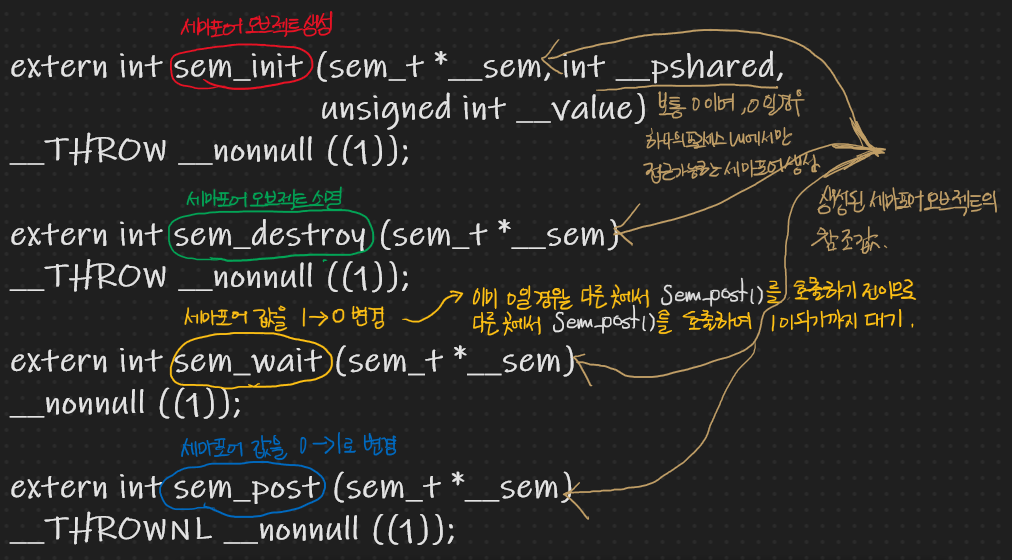
C기반 I/O Multithreading - 15. 뮤텍스와 세마포어(1)
C기반 I/O Multithreading - 14. 쓰레드의 치명적인 문제점 C기반 I/O MultiThreading - 12. 멀티 프로세싱? 멀티 쓰레딩? 멀티 프로세싱에 이어서, 멀티 프로세싱의 단점이 보완되는 멀티 쓰레딩 개념이다. 사
typingdog.tistory.com
C기반 I/O Multithreading - 16. 뮤텍스와 세마포어(2)
C기반 I/O Multithreading - 15. 뮤텍스와 세마포어(1) C기반 I/O Multithreading - 14. 쓰레드의 치명적인 문제점 C기반 I/O MultiThreading - 12. 멀티 프로세싱? 멀티 쓰레딩? 멀티 프로세싱에 이어서, 멀티 프..
typingdog.tistory.com
멀티 스레드와 이전 포스팅 시리즈(?)들이다.
이번에는 멀티 스레드를 기반으로 하며 Mutex 쓰레드 동기화 방법이 사용된 서버를 작성해볼 것이다.

위와 같은 쓰레드들 간에 공유가 가능한 데이터 영역의 변수들에 동기화 되지 않은 접근은 허용하지 않는다.

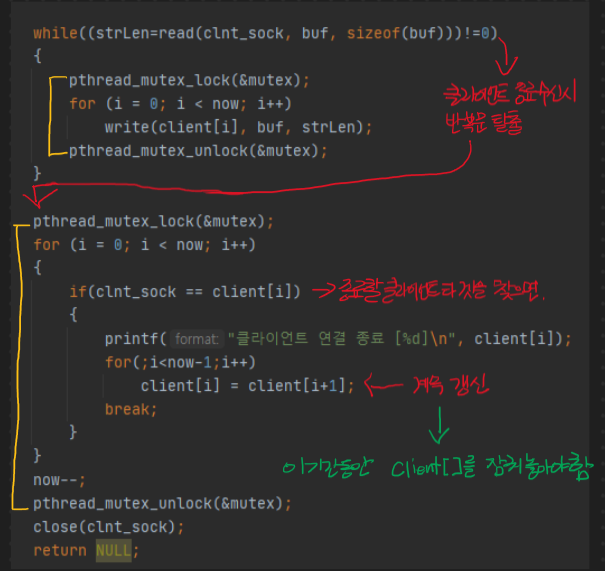
마찬가지로 데이터 메모리 영역에 접근하는 부분은 모두 동기화 시킨다.
코드 및 실행 결과
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
|
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <arpa/inet.h>
#include <pthread.h>
#define BUFSIZE 30
#define MAXCLIENTS 30
pthread_mutex_t mutex;
int client[MAXCLIENTS] = { 0, };
int now = 0;
void * HandleClient(void * arg);
void ErrorMsg(const char *msg);
int main(void)
{
pthread_t tid;
int serv_sock, clnt_sock;
struct sockaddr_in serv_addr, clnt_addr;
socklen_t addr_size;
pthread_mutex_init(&mutex, NULL); // 뮤텍스 id 생성
serv_sock = socket(PF_INET,SOCK_STREAM,0);
if(serv_sock == -1)
ErrorMsg("socket() error");
memset(&serv_addr,0,sizeof(serv_addr));
serv_addr.sin_family = AF_INET;
serv_addr.sin_addr.s_addr = htonl(INADDR_ANY);
serv_addr.sin_port = htons(7010);
if(bind(serv_sock, (struct sockaddr *)&serv_addr, sizeof(serv_addr)) == -1)
ErrorMsg("bind() error");
if(listen(serv_sock, 5) == -1)
ErrorMsg("listen() error");
while(1)
{
addr_size = sizeof(clnt_addr);
clnt_sock = accept(serv_sock, (struct sockaddr *)&clnt_addr, &addr_size);
if(clnt_sock == -1)
continue;
pthread_mutex_lock(&mutex);
client[now++] = clnt_sock;
pthread_mutex_unlock(&mutex);
pthread_create(&tid, NULL, HandleClient, (void*)&clnt_sock);
pthread_detach(tid);
printf("클라이언트 연결 [%d]\n", clnt_sock);
}
return 0;
}
void * HandleClient(void * arg)
{
int clnt_sock = *((int*)arg);
int strLen, state;
char buf[BUFSIZE];
int i = 0;
while((strLen=read(clnt_sock, buf, sizeof(buf)))!=0)
{
pthread_mutex_lock(&mutex);
for (i = 0; i < now; i++)
write(client[i], buf, strLen);
pthread_mutex_unlock(&mutex);
}
pthread_mutex_lock(&mutex);
for (i = 0; i < now; i++)
{
if(clnt_sock == client[i])
{
printf("클라이언트 연결 종료 [%d]\n", client[i]);
for(;i<now-1;i++)
client[i] = client[i+1];
break;
}
}
now--;
pthread_mutex_unlock(&mutex);
close(clnt_sock);
return NULL;
}
void ErrorMsg(const char *msg)
{
fputs(msg, stderr);
fputc('\n',stderr);
exit(1);
}
|
cs |

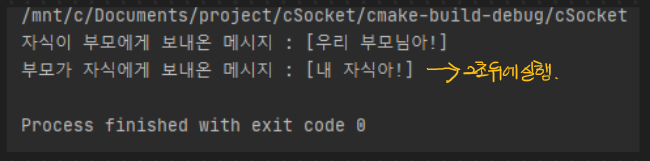
문제 없이 통신이 잘 되는 모습이다. 접속한 클라이언트의 수가 너무 적어서 사실 확실히 확인한 케이스는 절대 아니지만 코드적으로만 보아도 의미가 있기 때문에 이것으로 마무리 짓겠다.
'프로그래밍응용 > Socket' 카테고리의 다른 글
| C기반 I/O Multithreading - 16. 뮤텍스와 세마포어(2) (0) | 2021.02.05 |
|---|---|
| C기반 I/O Multithreading - 15. 뮤텍스와 세마포어(1) (0) | 2021.02.04 |
| C기반 I/O Multithreading - 14. 쓰레드의 치명적인 문제점 (0) | 2021.02.04 |
| C기반 I/O Multithreading - 13. 쓰레드의 생성과 소멸까지 (0) | 2021.02.03 |
| C기반 I/O Multithreading - 12. 멀티 프로세싱? 멀티 쓰레딩? (0) | 2021.02.03 |