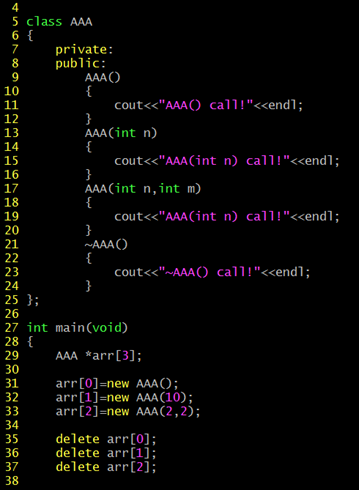
객체 배열은 다음과 같이 일반 배열 방식으로 선언할 수도 있으며, 동적 할당을 통한 방식으로 선언할 수 있다.
다만, 동적 할당이든 일반 배열이든 객체 배열을 선언할 때에는 각 배열의 요소 객체들마다 생성자 및 소멸자를 호출하지만 생성자의 경우 호출할 생성자를 명시하지 못한다 인자 전달이 불가능하고 무조건 인자가 없는 생성자만을 호출한다. 즉, 인자가 없는 생성자가 반드시 정의되어 있어야 한다. 각 배열의 요소를 초기화 시키기 위해서는 일일이 초기화를 시켜줘야 한다.
객체 포인터 배열
객체 포인터 배열은 객체의 주소 값 저장이 가능한 포인터 변수로 이뤄진 배열이다.
this 포인터
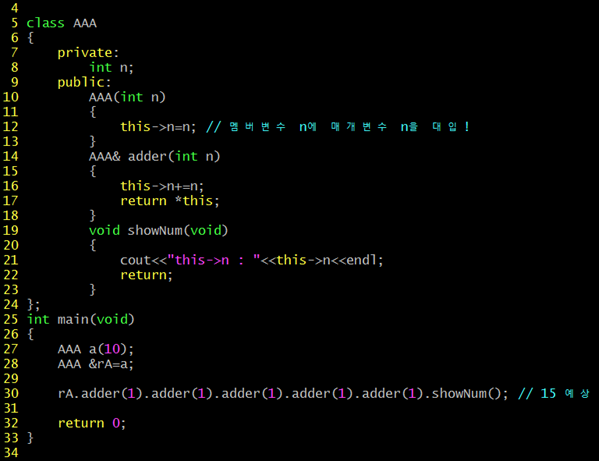
this 포인터는 객체 자신을 가리키는 용도로 사용되는 포인터로 멤버 함수 내에서 this라는 이름으로 사용할 수 있는 포인터이다. 객체 자신의 주소 값을 나타내는 포인터이다.
11번 라인에서 출력한 this 포인터를 출력한 결과와 17번 라인의 객체 a의 주소 값을 출력한 결과가 같은 것으로 보아 this 포인터는 객체 자기자신의 주소를 나타내는 포인터이며 다음과 같이 활용한다.
자기 참조자의 반환
This 포인터를 이용하여 자기 참조가 가능하도록 참조 정보를 반환할 수 있다. 17번 라인에서 참조 정보가 반환되고, 30번 라인에서 거듭된 접근 연산을 통해 멤버 함수를 호출하는데 이는 참조 값을 반환하고 그 반환된 참조 값을 이용해서 다시 접근하기를 반복하기 때문에 가능하다.
28번 라인에서 대입 연산자를 기준으로 a의 참조 정보(참조 값이) rA 참조자에 전달이 된다.
생성자는 먼저 클래스의 이름과 동일한 함수의 형태를 띄고 있으며, 반환형이 선언되어 있지 않으며, 실제로 반환 또한 하지 않는다.
생성자의 특징으로는 객체 생성 시 딱 한번 호출되며, 함수의 일종이니 오버로딩이 가능하며, 디폴트 매개변수를 설정할 수 있다. 그리고 객체가 생성될 때에는 생성자가 무조건 호출된다. 생성자가 호출되지 않고서 객체가 생성될 수 없다.
위의 예제는 생성자를 선언하고 활용하는 예이다. 11번 라인부터 23번 라인에서는 생성자를 정의하고 있는데 생성자도 일종의 함수이기 때문에 함수 오버로딩이 적용되고, 디폴트 매개변수의 적용 또한 가능함을 볼 수 있다. 그리고 29번 라인 ~ 42번 라인까지 일반 변수 형태의 선언과 동적 할당 형태의 선언으로 나뉘어서 각각 선언될 시 생성자의 호출을 볼 수 있다. 32번 라인의 형태는 객체가 생성되지 않는다. 왜냐하면 반환 타입이 AAA형이고 매개 변수는 void형이고 함수 이름이 a0인 함수의 원형 선언으로 간주되기 때문이다.
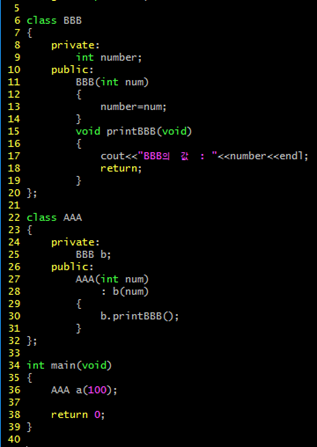
멤버 이니셜라이저
다음 상황에서 멤버 이니셜라이저는 멤버 변수로 선언된 객체의 생성자 호출에 활용된다.
28번 라인을 통해서 멤버 이니셜라이저를 진행하고 있는데 AAA 클래스는 BBB의 클래스의 객체를 멤버 변수로 가지고 있다. 객체 b의 초기화는 첫 번째 방법으로는 객체 b를 이용하여 set 함수를 통해 혹은 그에 준하는 함수의 호출을 통해 정보 은닉에 위배되지 않게 b 객체의 number 멤버 변수를 초기화 시키거나, 두 번째 방법으로는 생성자를 이용하여 초기화를 시켜야 한다. 그러나 위와 같이 클래스 내에서 선언되어 객체의 생성과 동시에 초기화 값 전달이 불가능하다. (BBB b(123) 형태의 선언이 불가능하다는 의미) 그러나 멤버 이니셜라이저를 이용하면 객체 형태의 멤버의 생성자를 이용한 초기화가 가능하다. 28번 라인의 내용이 멤버 이니셜라이저이다. 위 예제에서의 의미는 “객체 b의 생성 과정에서 num을 인자로 전달받는 생성자를 호출한다” 라는 의미이다.
위와 같이 객체가 아닌 일반 기본 자료형에 대한 멤버 변수 또한 이니셜라이저를 통해서 초기화가 가능하다. 12번 라인처럼 멤버 변수 num을 생성자를 통해 넘겨온 매개 변수 n을 이용하여 초기화 하라는 의미이다. 이렇게 되면 멤버 변수를 초기화 하는 방법은 두 가지가 된다.
1.생성자의 몸체에서 초기화 2.이니셜라이저를 이용한 초기화
두 가지가 존재하는데 이니셜라이저를 통하여 초기화를 진행하는 경우 다음과 같은 이점을 얻을 수 있다.
1.초기화의 대상을 명확히 인식할 수 있다. 2.성능에 약간의 이점이 있다. ->선언과 동시에 초기화가 이뤄지는 형태로 바이너리 코드가 생성된다. -> 생성자 몸체의 경우 int num; num=10;/이니셜라이저의 경우 int num=10; 효과를 볼 수 있다.
const 멤버 변수/참조자 멤버 변수의 초기화
이니셜라이저를 이용할 경우 “선언과 동시에 초기화”와 같은 효과를 얻는다는 이유로 const 멤버 변수의 초기화를 진행할 수 있다! 또한 선언과 동시에 초기화가 이루어져야 하는 참조자 멤버 변수 또한 초기화가 가능하다.
객체 생성 과정의 정리
1.메모리 공간의 할당 2.이니셜라이저를 이용한 멤버 변수(객체)의 초기화 3.생성자의 몸체 부분 실행
모든 객체는 세 과정이 순서대로 거치고 생성이 완료된다.
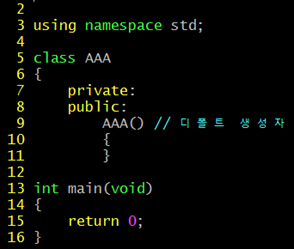
디폴트 생성자
객체가 되기 위해서는 반드시 하나의 생성자가 호출되어야 한다. 그러나 생성자가 없는 클래스의 경우 객체를 생성하지 못하는 것인가? 이런 문제를 해결하기 위해서 생성자를 정의하지 않은 클래스에는 C++ 컴파일러에 의해서 디폴트 생성자가 자동으로 삽입된다.
디폴트 생성자는 전달 인자를 받지 않고, 내부적으로 아무런 일도 하지 않는 생성자이다.
이러한 디폴트 생성자는 생성자가 하나도 정의되어 있지 않을 때만 컴파일러에 의해 자동으로 삽입된다. 다른 말로 생성자가 하나라도 추가되어 있다면 디폴트 생성자는 컴파일러에 의해 자동으로 삽입되지 않는다.
Private 생성자
클래스 내부에서만 객체의 생성을 허용하려는 목적으로 생성자를 private으로 선언.
소멸자
위와 같은 예에서 12번 라인과 같은 형태를 소멸자라고 한다.
소멸자는 클래스의 이름 앞에 ‘~’가 붙은 형태의 이름을 갖으며, 반환형이 선언되어 있지 않고 실제로 반환하지 않는다. 그리고 매개변수는 항상 void형으로 선언되어야 하고 오버로딩 및 디폴트 매개변수 설정 모두 불가능하다.
소멸자의 특징은 먼저 객체 소멸 과정에서 자동으로 호출이 된다. 그리고 아무런 소멸자가 생성되어 있지 않으면 디폴트 생성자가 컴파일러에 의해 자동으로 삽입된다. 소멸자는 생성자에서 할당한 리소스의 소멸에 사용된다.
벡터가 무엇인지 한번 찾아보았다. 간단하게 정의하자면 순차 컨테이너에 속하는 동적 배열이다. C의 배열과 똑같이 행동한다.
그렇다면 C의 배열과 벡터의 차이점은 무엇일까?
1. 타입에 상관없이 모든 타입에 대해서 일반적인 배열을 만들 수 있다. => int, double, char, int *, 객체 가릴 것 없이 모든 타입에 대해서 배열을 만들 수 있다는 이야기이다. 2. 배열의 크기 조절이 자동으로 이루어지며, 추가 및 삭제에 대한 인터페이스를 제공한다 => 배열에 값을 추가하기 위해 새롭게 더 큰 메모리를 할당하고, 값을 복사하고 기존 메모리를 해체하고... 이러한 과정들을 알아서 해준다는 것이다! 개꿀!!!!ㅋㅋㅋㅋㅋㅋㅋㅋㅋ
그러나 2번과 같은 장점에 따른 단점 또한 존재한다.
C++의 벡터는 무조건 데이터를 선형적으로 만들려고 한다.( 그렇기에 이름도 순차 컨테이너. ) 중간에 끊긴다거나 하면 안된다는 소리이다.
왼쪽과 같은 형태는 가능하지만, 오른쪽과 같은 형태는 안된다는 소리이다. 이러한 선형을 유지해야하는 특징 때문에 값을 추가할 때 단점이 발생한다.
메모리 공간이 충분하여 기존에 이어서 확장한 후 값을 그냥 더 추가할 경우에는 문제가 안된다. 아래의 그림처럼 말이야.
그런데 다음 그림과 같이 기존의 6개 메모리 뒤에 다른 관련없는 값이 이미 할당되어 기존의 6개 메모리 뒤에 연이어 추가 확장이 불가능한 경우는 문제가 발생한다.
이러한 경우에는
이렇게 복사, 확장, 추가, 소멸 등의 여러 작업들이 필요하니 속도가 느려지는 단점이 있다.
설명은 이 정도로 정리하도록 하고, 매우 간단한 코드를 기록해보자.
7번 라인에서 볼 수 있듯이 템플릿 문법을 활용하여 사용한다. 반복자를 활용하지 않은 가장 기본 기본 기본적인 벡터 예제이다. 실행 결과는 매우 뻔하기 때문에 생략~
9번 라인에서 처럼 .size() 함수를 통해 벡터가 정의된 길이를 확인할 수 있다.
다음 vector 에서 제공하는 push_back 함수를 사용한 예이다. push_back 함수를 사용하면 벡터 열에 손쉽게 데이터를 추가할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
#include<iostream>
#include<vector>
usingnamespacestd;
int main(void)
{
int max_number =0;
int val =0;
vector<int> num_vector;
while (true)
{
cout<<"벡터에 추가할 숫자를 입력하세요 (-123123 입력 시 종료) : ";
cin>> val;
if (val ==-123123)
break;
else
num_vector.push_back(val);
}
max_number = num_vector[0];
for (int i =0; i < num_vector.size(); i++)
{
if (num_vector[i] > max_number)
max_number = num_vector[i];
}
cout<<" 입력한 값 중에서 최대 값은 "<< max_number <<" 입니다."<<endl;
정보 은닉이란? 멤버 변수를 private 접근 제어 지시어로 선언하여 외부에서의 모든 접근을 차단하고, 해당 변수에 접근하는 함수를 별도로 정의해서, 안전한 형태로 멤버 변수의 접근 및 초기화, 갱신 등이 이루어지도록 유도하는 것이 정보 은닉이다.
이러한 정보 은닉이 나오게 된 이유는 멤버 변수의 외부 접근 허용으로 대입되는 값이 전혀 검증이 이루어지지않은 채로 대입되기 때문이다. 그렇기 때문에 외부의 접근을 허용하지 않고(private), 해당 멤버 변수에 접근할 수 있는 함수를 별도로 정의하고 그 함수 내에 해당 멤버 변수에 대입하려는 값에 대한 검사를 이룰 수 있도록 하는 것이다.
8번의 private 접근 제어 지시자를 통하여 정보 은닉의 조건 중 하나를 충족시켰고, 13번, 23번 라인에서 멤버 변수에 접근에 대해서 검증을 함으로써 정보 은닉을 성립시킨다. 13번, 23번, 33번, 34번 라인에서 get, set 함수를 볼 수 있는데 이러한 함수들을 엑세스 함수라고 한다. 이러한 엑세스 함수들은 당장 사용되지는 않지만 필요할 수 있는 가능성이 있기 때문에 항상 생성해두기도 한다.
const 함수
위의 예제에서 get 메소드에 대해서 변경된 부분이 있다.
Get 엑세스 함수에 const 키워드가 붙은 형태인데 이러한 함수를 const 함수라고 한다. 꼭 get 엑세스 함수만 적용되는 것이 아닌 모든 함수들이 const 키워드만 붙어 있다면 적용된다.
이러한 함수에 const가 붙게 되면 의미하게 되는 것은 이 함수 내에서는 멤버 변수에 저장된 값을 변경하지 않겠다 라는 의미를 갖게 된다. 즉, const 함수에서는 멤버 변수의 값을 변경하는 코드가 존재하면, 혹은 그럴 가능성, 변경할 수 있는 능력이 존재하는 코드가 존재한다면 컴파일 에러를 발생한다.
멤버 변수의 값을 변경할 수 있는 능력이나 가능성이 존재하는 코드란 const화 되지 않은 함수의 호출을 뜻한다. 왜냐하면 const화 되지 않은 함수는 호출됨으로써 멤버 변수를 어떠한 형태로든 변경할 수 있는 능력과 가능성이 존재하기 때문이다. 그렇기 때문에 const 함수 내에서는 const화 되지 않은 함수의 호출을 제한한다.
+ const 참조자를 이용한 함수 호출 또한 const화된 함수만을 호출할 수 있다.
위와 같은 두 가지 조건에 의해서 const 함수를 선언하고 사용하게 되면 많은 함수들을 const화 시켜야 한다. 그렇지만 그만큼 작성된 코드는 안정성이 높아진다.
캡슐화
캡슐화
캡슐화는 관련 있는 함수와 변수를 하나의 클래스 안에 묶는 것. 그러나 어려운 개념이다 왜냐하면 캡슐화의 범위를 결정하는 일이 쉽지 않기 때문이다.
소프트웨어란 데이터의 표현 + 데이터의 처리로 표현이 되는데, 여기서 데이터는 항상 관련 있는 주제, 특징, 특성에 따라 부류를 형성한다. 이러한 부류를 형성하는 데이터들은 항상 함께 생성되고, 함께 사용되고, 함께 소멸되는 특성이 있고, 그래야만 하는 경우가 대부분이다. 구조체는 연관 있는 데이터를 묶고 부류를 형성할 수 있도록 하는 문법적 장치이다.
위와 같이 구조체를 생성하고, 사용할 수 있다. 13번 라인에서는 C언어와 다르게 struct 키워드를 사용하지 않고 구조체를 선언할 수 있도록 문법적으로 구성되어 있다.
구조체에 함수 삽입하기
구조체는 연관 있는 부류의 데이터를 묵는 문법적인 수단이었다. 그렇다면 소프트웨어의 구성에서 데이터의 처리 부분에 해당하는 함수 또한 관련 데이터 부류와 함께 묶어서 처리하면 되지 않을까?
위의 예제에서 데이터 표현 부분은 관련 부류를 형성하여 구조체를 이루었다. 그러나 deposit, withdraw 함수는 기능적으로 account 구조체의 데이터 부류에 대해서 처리를 담당하는 함수 임에도 불구하고 구조체와 서로 분리되어 있다. 이 함수들 또한 부류를 형성하여 같이 묶는다면 다음과 같다.
<a. 멤버 함수를 클래스 내부에 정의> <b. 멤버 함수를 클래스 외부에 정의>
관련 있는 부류의 데이터와 처리에 해당하는 모든 부분을 하나의 구조체에 넣은 형태이다. 이런 식으로 구조체안으로 들어간 함수를 해당 구조체의 멤버 함수라고 한다. 구조체로 들어간 함수를 호출할 때에는 a 그림의 32번 라인, 33번 라인과 같이 구조체의 멤버 변수를 지정할 때와 마찬가지로 직접 접근 연산자 (혹은 포인터의 경우 간접 접근 연산자)를 이용하여 함수를 호출한다.
그림 a와 그림 b의 차이는 함수의 정의를 구조체 내부에 하는지, 구조체 외부로 따로 정의하는 지의 차이이다. 함수의 정의가 너무 길고 복잡할 때에는 가독성을 위해 함수의 선언 만을 구조체 정의 내부에 두고 함수의 정의는 구조체 외부에 따로 둔다. 이 때 구조체 이름과 범위 지정 연산자를 이용하여 함수의 정의를 외부에 두는데 그림 b의 25, 31, 36번 라인과 같은 형식으로 정의하면 된다. 구조체 내부에 함수의 정의가 존재하면 함수를 인라인(in-line)으로 처리하라는 의미이다. 함수를 구조체 외부에 둔 경우에 인라인 처리를 원한다면 따로 출력 타입 앞에 inline 키워드를 넣음으로써 인라인 화 할 수 있다.
지금까지의 구조체는 모두 클래스의 일종으로 간주되며, 멤버 변수와 멤버 함수를 넣을 수 있었던 것 모두 클래스의 일종이기 때문이고 이러한 정의의 구조체를 ‘클래스’ 라고 표현할 수 있다.
클래스와 구조체의 차이점
위의 왼쪽 예는 구조체라고 정의되어 있지만 사실 멤버 함수를 포함할 수 있는 클래스의 일종 혹은 클래스라고 할 수 있다. 그렇기 때문에 오른쪽과 같이 키워드를 class로 변경하고 클래스를 정의한다.
그러나 왼쪽 16번 라인에서 구조체일 때는 가능했던 초기화가 클래스로서 인정하고 변경을 하고 보니 오른쪽 16번 라인에서는 초기화가 불가능하다. 16번 라인과 같은 초기화 뿐만 아니라 다음과 같은 경우도 불가능하다.
위의 예의 공통점들은 클래스의 외부에서 클래스 내의 모든 멤버들에 접근하여 쓰는 혹은 읽는 작업을 하고 있다. 즉 외부에서 접근한다는 것이 공통점이다. 외부에서 접근하는 모든 문장에 대해서는 컴파일 에러를 내고 있다.
클래스는 접근에 대한 지시를 따로 명시하지 않는다면 기본적으로 외부로부터의 모든 접근을 허용하지 않으며, 이 때 클래스 내에서 선언된 모든 멤버들은 모두 클래스 내에서만 접근하는 내부 접근만 가능하다. 이렇게 클래스는 구조체와 다르게 외부 접근에 대해서 허용 범위를 별도로 선언해야 하는 것이 차이점이다.
접근 제어 지시자(접근 제어 레이블)
위의 예제는 접근 제어 지시자를 적용한 account 클래스를 나타낸 것이다. 먼저 접근 제어 지시자의 효력의 범위는 접근 제어 지시자를 명시한 라인부터 다음 접근 제어 지시자가 나오는 라인 바로 전 까지가 효력이 끼치는 범위이다.즉, 8번 라인의 private 영역의 효력은 다음 접근 제어 지시자인 public의 바로 전 라인인 11번 라인까지 private의 효력을 유지한다. 8번 라인부터 11번 라인까지 있는 멤버 변수들은 외부에서 접근이 절대적으로 금지된다. 반면에 12번 라인부터 클래스의 끝 까지는 public 접근 제어 지시자의 영역으로 멤버 함수들에 대해서는 외부에서의 접근을 허용한다. 그러므로 외부에서는 account 클래스의 멤버 함수에 접근하여 원하는 기능을 실행할 수 있도록 적절한 멤버 함수를 정의 및 선언해주어야 하고, 이러한 멤버 함수를 통해 멤버 변수의 조작이 이루어져야 한다. 아니 그렇게 설계되어야 한다!
파일 분할 시 클래스의 선언과 정의에 대한 정보
클래스의 선언
컴파일러가 클래스와 관련된 문장의 오류를 잡아내는데 필요한 최소한의 정보, 클래스를 구성하는 외형적인 틀을 보여준다. 위의 예에서 account 클래스와 관련된 문장의 옳고 그름을 판단하는데 사용된다.
-> 컴파일의 정보로 사용되므로 헤더 파일에 저장한 후, 필요한 위치에 포함될 수 있도록 하면 됨. 단, 인라인 함수의 경우에는 함수 정의가 분리되었다고 하더라도 헤더 파일에 함께 포함해야 한다. 왜냐하면? 컴파일 과정에서 함수의 호출 문이 있는 곳에 함수의 몸체가 대치되어야 하기 때문이다.
클래스의 정의
멤버 함수의 정의는 다른 문장의 컴파일에 필요한 정보를 가지고 있지 않다. 따라서 컴파일 된 이후에 링커에 의해 하나의 실행파일로 묶이기만 하면 된다.
-> 소스 파일에 저장해서 컴파일이 되도록 하면 된다.
객체지향 프로그래밍
먼저, 객체는 현실에 존재하는 모든 사물 또는 대상이 될 수 있다. 이런 객체의 개념을 이용한 객체지향 프로그래밍이란? 현실에 존재하는 사물과 대상, 그리고 그에 따른 행동을 있는 그대로 실체화를 시키는 형태의 프로그래밍
이러한 객체를 이루는 것은 하나 이상의 상태 정보(데이터)와 하나 이상의 행동(기능)으로 구성된다.
클래스 기반의 객체 생성 방법 및 활용 (두 가지)
- 일반적인 변수 선언 방식
- 동적 할당 방식
Message Passing 방법
-> 하나의 객체가 다른 하나의 객체에게 메시지를 전달하는 방법은 함수 호출을 기반으로 한다! 함수 호출을 기반으로 하는 객체 간의 대화법에서 함수 호출하는 행위를 메시지 전달이라고 함.
오늘은 컨테이너, 이터레이터, 알고리즘이란 무엇이며, 무엇이 있는지 학습한 결과를 기록한다.
Container
컨테이너는 뜻 그대로 그릇, 무언가 담을 수 있는 역할을 한다. 즉, 자료 및 값을 저장하는 역할을 한다. 이 그릇의 모양이나 크기에 따라 담기를 권장되는 내용물이 다르고 취급 방법이 다르다.(컵이라는 그릇에 라면을 담을 수는 있지만 효율적이지 못한 것처럼.)
먼저, 컨테이너에는 순차 컨테이너, 연관 컨테이너, 컨테이너 어댑터 등이 있다.
이게 무슨 소리인가?
순차 컨테이너 : 뭔가 자료들이 순차적으로 들어가는거..? 연관 컨테이너 : 연관되어서 들어가는거..? 쌍으로 연관되어서 들어가는 것인가? 컨테이너 어댑터 : 어댑터란 다른 전기나 기계 장치를 서로 연결해서 작동할 수 있도록 만들어 주는 결합 도구 라는 정의가 있는 것으로 보아, 컨테이너와 컨테이너를 변환할 수 있는 그런게 아닐까?
나는 리얼로 위와 같이 생각했다. 내가 조사해 본 컨테이너들은 다음과 같다.
순차 컨테이너
말 그대로 순차적으로 자료를 저장한다. 내 예측이 맞았다! 순차 컨테이너에서는 자료의 추가가 빠르지만 탐색할 때에는 시간이 많이 걸린다. 왜냐하면 순차적으로 접근하기 때문에!
이러한 순차 컨테이너에는 vector, deque, list 가 있다. 그렇게 벡터, 벡터했던게 바로 여기서 나오는 개념이었구나~
1. Vector : 동적 배열 처럼 동작하며, 자료는 뒤 쪽에서 추가된다. 2. Deque : 벡터와 유사하지만 앞에서도 자료들이 추가될 수 있다. 3. List : 벡터와 유사하지만 중간에서 자료를 추가하는 연산이 효율적이다.
연관 컨테이너
다음은 연관 컨테이너이다. 연관 컨테이너는 조사해 본 결과 사전과 같은 구조로 자료를 저장한다고 한다. 즉, 키와 값의 형태로 데이터가 저장되고, 자료들은 정렬되어 있으며 이러한 정렬 때문에 자료 추가에는 시간이 걸리지만 탐색은 키를 통하여 한 번에 뽑아내니 빠르다.
이러한 연관 컨테이너에는 Set, Map, MultiSet, MultiMap 등이 있다
1. set : 집합이라고 하며, 중복이 없는 자료들이 정렬되어 저장된다. 2. map : 맵이라고 하며, key - value 형태로 저장된다. 3. multiset : 다중 집합이라고 하며, 집합과 유사하지만 자료의 중복을 허용한다. 4. multimap : 다중 맵이라고 하며, 맵과 유사하지만 키가 중복될 수 있다.
컨테이너 어댑터
드디어 컨테이너 어댑터이다!
컨테이너 어댑터는 기존 컨테이너의 인터페이시를 제한하여 만든 기능이 제한되거나 변형된 컨테이너를 의미한다고 한다. 이게 무슨 말일까 싶어서 좀 더 확인해보았는데
컨테이너 어댑터에는 Stack이 있다. 이를 예로 들자면, 기본 컨테이너인 벡터는 vector 클래스를 사용하는데 이 클래스의 인터페이스를 제한하고(벡터의 여러 기능들을 제한하고) 특정 형태(스택에 관련된 연산)의 동작 만을 수행하도록 한다.
그러니까 한 마디로 내가 어떤 자료구조를 구현할 것 인데 그냥 밑 바닥부터 구현하기 힘들고 귀찮은데 마침 기가 막히고 검증된 기존의 컨테이너가 있으니 이를 활용하여 확장 및 축소 등의 적용(Adapt)을 하는 것이라고 보면 될 것 같다. 그런데 뭔가 계속 제한한다고 하는데 이는 기존의 컨테이너에서 필요없는 부분은 사용하지 못하도록 하는 의미의 제한인 것 같다.
아무튼, 이러한 컨테이너 어댑터에는 Stack, Queue, Priority queue이 제공된다.
Iterator
이제는 반복자(Iterator)의 개념이다.
이 반복자는 각 컨테이너의 자료구조에 맞는 액세스를 할 수 있도록 도와준다. 예를 들어 순회를 한다거나, 원하는 값이 있는 메모리에 접근 가능하도록. 검증되었기 때문에 안심하고 사용해도 된다.
일종의 포인터와 비슷한 객체이다. 기존의 자료구조에서 보면 링크드 리스트에서만 보더라도 노드를 순회하기 위해서는 포인터의 값을 증가 혹은 감소시키고 여러 검사를 하는 등 작업을 했는데 반복자가 이를 대신해준다고 보면 된다.
알고리즘마다 각기 다른 방식으로 컨테이너 요소들에 접근하기 때문에 반복자에도 여러 종류들이 존재한다. 그렇기 때문에 컨테이너를 사용한다면 꼭 반복자를 사용해야 한다.
반복자에는 몇 가지 예를 들자면 input iterator, output iterator, forward iterator, bidirectional iterator, random access iterator 등이 있다.
Algorithm
알고리즘은 문제 해결하기 위해서 그 절차나 방법의 공식화를 의미한다.
탐색, 정렬, 반전, 삭제, 변환 등이 있다.
위와 같이 3가지 요소로 구성된 것이 C++ STL이라는 것을 학습했고, 대충 개념을 잡게 되었다.
참조자란 할당된 메모리 공간에 둘 이상의 이름을 부여하는 것으로 다시 말하면 참조자는 자신이 참조하는 변수를 대신할 수 있는 또 하나의 이름
다음은 참조자를 사용하는 예제이다.
10번 라인에서 & 연산자를 이용하여 참조자(레퍼런스)를 선언하고, 변수 num에 대해서 참조를 진행한다. 참조자 선언과 참조를 마친 후 13번 라인에서 일반 변수 num과 레퍼런스 ref의 주소를 출력해보았을 때 완전히 같은 주소를 출력하는 것을 확인할 수 있는 것으로 미루어 보아, 기존의 대상이 되는 변수에 이름만 부여되는 것임을 확인할 수 있다. 즉, 참조자는 이름을 하나 더 부여하는 별칭인 셈이다.
그리고 하나의 변수에 대해 여러 참조자를 선언하고 참조할 수 있으며, 참조자를 대상으로 참조자를 선언할 수 있다.
9번 라인부터 13번 라인까지 대상 변수에 대한 참조자의 수, 참조자를 대상으로 하는 거듭된 참조까지 가능함을 알 수 있다. 그리고 19번 라인에서 대상 변수 그리고 참조자들의 주소를 출력했을 때 모두 대상 변수의 주소로 같게 나왔음을 확인할 수 있다.
참조자의 잘못된 선언 형태에 대한 간단한 예제이다.
먼저, 10번 라인에서는 참조자를 선언만 하고, 참조를 하지 않은 상태인데 참조자는 선언과 동시에 어떤 대상을 꼭 참조해야만 한다. 그리고 11번 라인에서는 선언과 동시에 참조를 진행했지만 참조의 대상은 참조자의 타입이 맞는 변수가 대상이어야 한다. 마지막 12번 라인에서는 NULL로 선언과 동시에 참조를 하고 있지만 역시 마찬가지로 변수가 대상이 아니기 때문에 참조가 불가능하다. 이와 더불어 한 번 참조가 된 이후에는 참조의 대상 변경이 불가능하다.
참조의 가능 범위는 다음과 같이 크게 3가지가 존재한다.
일반 변수
배열 요소
포인터 변수
참조자와 함수
Call-By-Address와 Call-By-Reference 모두 주소 값을 인자로 전달하는 형태의 함수 호출은 뜻하는데, 그 사실 보다는 주소 값을 전달하되, 해당 주소를 이용하여 참조 혹은 값의 변경이 일어났는가를 볼 수 있어야 함. (결국, call-by-address와 call-by-reference 방법은 서로 비슷한 방법이라고 보일 수 있지만 전자는 단지 주소만을 전달하느냐 후자는 주소를 전달하고 참조를 행하느냐를 보는 것인데 전자의 경우는 주소만 전달될 뿐 참조가 일어나지 않기 때문에 call-by-value로 볼 수도 있음 그렇기 때문에 두 용어는 구분이 필요함을 이야기함.)
다음은 참조자를 이용한 swap 함수의 구현이다.
Const 참조자
참조자를 이용하여 call-by-reference를 구현할 때, 매개 변수에 참조자를 const화 시켜서 넣게 되면 해당 참조자 매개 변수를 이용하여 값의 변경을 허용하지 않겠다 라는 의미를 갖는다.
이러한 의미가 왜 필요한가?
위와 같은 예제를 마주쳤을 때, C언어에서는 num의 값이 바뀌지 않는 call-by-value 방식의 호출이라는 것을 위 예제만 보고도 알 수 있으나, C++언어에서는 참조자의 개념 때문에 call-by-reference인지 call-by-value인지 알 수가 없다. 이를 확인하기 위해서는 함수의 원형을 확인해야 하고 뿐만 아니라 정의까지 확인해야한다. (왜냐하면 참조자로 매개 변수를 선언했을지라도 참조 후 값의 변경이 있는지 없는지는 정의를 확인해야하기 때문이다.) 이러한 불편함을 해소하기 위해서 함수의 원형 선언만 보더라도 const 키워드로 인해 값의 변경이 일어나는지 일어나지 않는지를 확인할 수 있게 해준다. 다음과 같이.
그리고 const 참조자에는 이러한 경우도 있는데,
16번 라인에서 const를 이용한 변수의 상수화로 심볼릭 상수를 선언하였고, 17번 라인에서 ref 참조자로 심볼릭 상수와 참조 관계를 형성한다. 그리고 18번 라인에서 참조자를 통한 값의 변경을 행한다. 기껏 16번 라인에서 상수로 만들었는데 참조자를 통한 값을 변경을 하고 있다. 그러나 이는 허용하지 않는다. 17번 라인 참조 관계를 형성하는 부분에서부터 허용을 하지 않는다 왜냐하면?
C언어 정리에서 언급했듯이 대입 연산자를 기준으로 l-value 와 r-value의 자료형은 완벽하게 같아야 대입이 이루어지는데 현재 17번 라인에서는 l-value의 타입은 int& 이고, r-value의 타입은 const int 이다. 이는 다른 타입이기 때문에 대입에서 오류가 나는 것임.
그래서 위와 같이 맞춰 주어야만 오류가 나지 않는다.
또 const 참조자는 상수를 참조할 수 있는 특징을 가지고 있다.일반 참조자와 다르게 const 참조자를 이용해서상수와 참조 관계를 형성하려고 하면 상수가 해당 라인이 넘어가면 소멸되는 리터럴 상수가 아닌 임시 변수 형태로 생성되어 그 값을 가지고 있는 형태로 생성된다. 그렇기 때문에 그 임시 변수 공간과 참조 관계를 형성할 수 있는 것이다.
15번 라인에서 50이라는 임시 변수를 생성하고 그 임시 변수의 공간에 ref 이름을 부여한다. 7번 라인과 16번 라인 또한 같은 맥락이다.
함수의 출력 타입이 참조형인 경우
위와 같은 함수 정의에서 14번 라인의 경우에는 arg 변수에 대한 새로운 참조 관계가 형성되는 경우이고, 15번 라인에서는 200이라고 하는 값이 반환된 것이고 v에는 값이 저장되는 경우이다.
위와 같은 경우에는 반환 값을 참조가 아닌 일반 자료형으로 지정한 경우인데 이 경우 반환되는 값은 단순히 값만 반환되기 때문에 일반 변수로 값을 리턴 값을 받을 수 있지만, 25번 라인처럼 참조 관계를 형성할 수는 없다 왜냐하면 int& r = 200; 형태와 같은 형태이기 때문이다.
위와 같이 함수 내의 지역 특성을 지니는 지역 변수에 대해서 참조 관계를 형성시켜서는 안된다(왼쪽). 이는 포인터로 지역 변수에 대해서 가리키고 참조하는 것과 다를 것이 없다.(오른쪽). 함수가 종료되면 사라지는 지역적 특성을 지니는 지역 변수를 함수의 외부(함수 종료 상태의 지역)에서 참조한다는 것은 이미 해체되어 없는 공간 혹은 다른 쓰레드 작업에 의해 이미 다른 중요 값으로 채워져 있는 공간을 참조하고 조작할 수 있는 가능성이 있기 때문에 잘못된 것.
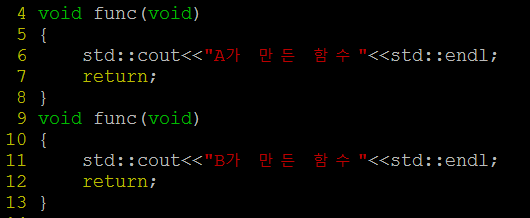
위와 같은 예제에서는 두 함수 모두 수행하는 내용은 다르지만 이름, 매개 변수가 같다는 이유로 오버로딩이 적용되지 않고 에러가 난다. 예제에서는 나타나지 않지만 두 함수 모두 다른 모듈이나 소스에 이미 의존되어 있는 부분이 있기 때문에 이름을 바꾸거나 할 수 없다. 이러한 경우 이름 공간을 이용한다.
위의 예제에서는 각 함수를 A, B라는 이름 공간(namespace) 으로 감싸고, 영역을 구분하였다. 영역을 구분하였기 때문에 함수 중복 문제로 오류가 발생하지 않는다. 그리고 24, 25번 라인에서는 ‘ :: ’ 범위 지정 연산자를 이용하여 이름 공간을 지정하여 그 내부의 함수를 지정하여 호출하는 식으로 함수 호출을 진행함.
이름 공간 기반의 함수 선언과 정의 구분
이름 공간에서 동일한 이름 공간 내의 함수 호출 및 변수 참조가 일어날 경우 범위 지정 연산자를 이용하여 이름 공간을 명시할 필요가 없다.
이름 공간의 중첩
이름 공간은 중첩이 가능하고, 범위 지정 연산자를 거듭 이용하여 범위를 지정하고 변수나 함수에 접근한다.
이름 공간 std
std::cout, std::cin, std::endl 등은 모두 이름 공간 내의 어떤 요소들이었다.
위와 같은 형태로 존재하고 있는 요소들이고, cout/cin/endl 은 추후에 정리.
using 연산자를 이용한 이름 공간의 명시
위와 같이 이름 공간 전체를 명시하여 이름 공간의 범위 지정 연산을 생략할 수 있다.
위와 같이 이름 공간 내의 특정 요소를 지정하여 이름 공간 범위 지정을 생략할 수 있다.
아래는 이름 공간을 명시 혹은 이름 공간 내의 특정 요소에 이름 공간을 명시하여 범위 지정 연산을 생략한 예를 보여준다.