원래 기존에 Desktop도 리눅스 우분투를 사용하는 나는 이를 설치를 안 할 수 없었다.
요즘 윈도우에서 동작하는 클라이언트 프로그램에 대한 서버를 만드느라 윈도우에서 개발을 하다보니 Visual Studio를 이용한 개발이 한창이었다. 그런데 이제는 우분투에서는 Visual Studio가 없으니 CLion으로 갈아타야하는데, CLion은 내가 알기로는 CMake 설정을 직접하는 형태인 것이다. 그래서 CMake를 일단 서버에 설치를 해야한다.
그래서 이번 시간에는 CMake 설치하는 시간을 갖도록 하겠다.
CMake를 설치하기 이전에 CMake가 무엇인지 아주아주 간단하게 정리를 해보겠다.
1. CMake란?
CMake를 논하기 이전에 Make가 무엇인지, C언어 계열의 프로그램 작성 방법에 대해서 알아야한다.
C 계열의 프로그램 작성 방법
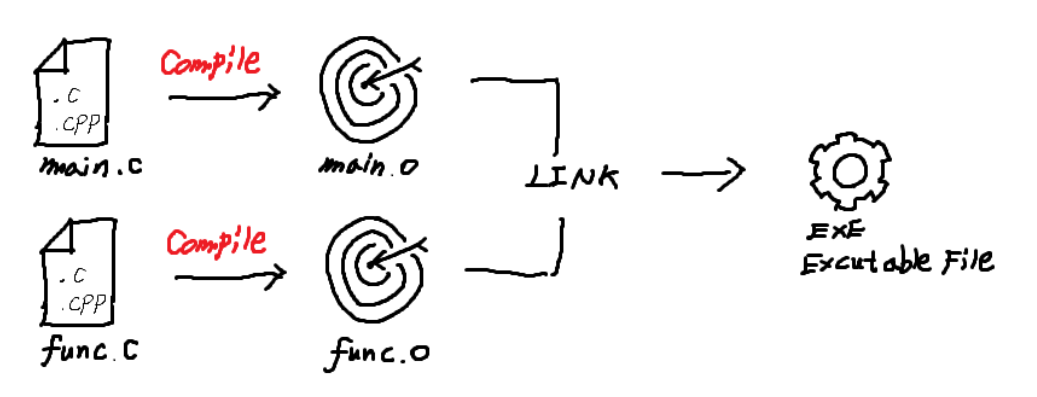
그리는데 너무 힘들었다 ㅋ
위의 그림과 같은 방법으로 프로그램이 작성이 된다. 예에서 나온 그림을 gcc 컴파일 명령어를 통해 나타내면 다음과 같다.
gcc 혹은 g++ 컴파일러를 이용하여 컴파일을 진행할 경우 위처럼 각 소스 프로그램마다의 목적 파일을 생성하고 이를 연결해주는 링크 작업을 진행한다.
Make
자! 그러면 Make를 설명할 때가 되었다. Make는 위의 명령들을 순차적으로, 자동적으로 실행하여 빌드하도록 돕는 파일 관리 유틸이다.
CMake
CMake 는 멀티플랫폼으로 사용할 수 있는 Make의 대용품을 만들기 위한 오픈 소스 프로젝트라고 하는데, 사실 따지고 보면 위의 Make 파일을 만들어주는 유틸인 것이다. 즉, (빌드를 돕는) (Make를 만들어내는) 그것이 바로 CMake인 것이다.
정말 간단하게 말해서 CMake는 Make가 잘 동작하도록 도와주고 Make는 컴파일을 위한 명령들이 순차적으로 실행될 수 있도록 돕는 것이다.
2. 설치 방법
2-1 . Cmake 3.18.4 버전을 따로 설치할 것이니 기존의 설치가 존재한다면 지운다!
sudo apt purge cmake
2-2 . 필요한 패키지를 설치한다.
sudo apt install wget build-essential
2-3 . Cmake 빌드를 위한 OpenSSL을 설치한다.
wget https://www.openssl.org/source/openssl-1.1.1h.tar.gz # oepnssl 다운로드 tar xzvf ./openssl-1.1.1h.tar.gz # 압축 해제 cd openssl-1.1.1h # 이동 ./config # 빌드 전 config make make test # 빌드 준비 sudo make install # 빌드 시작
구조체란 하나 이상의 변수를 묶어서 새로운 자료형을 정의하는 도구이다. 예를 들어, 기존의 자료형과 별개로 3바이트짜리 자료형을 만들어내는 것, 이러한 예처럼 새로운 자료형을 기본 제공 자료형으로 추가하는 것은 불가능 하지만 기존의 자료형들을 이용하여 생성하는 변수들을 묶어서 새로운 자료형을 정의하는 것은 가능하다.
다음은 이름과 학번을 저장하는 새로운 자료형을 정의한 예를 나타낸 것이다.
학생을 관리하는 시스템에서는 학번과 이름은 함께 처리되어야 의미가 있는 자료들이다. 그렇기 때문에 위와 같이 학생의 이름을 나타내는 name 변수와 해당 이름의 학생의 번호를 의미하는 stdNum을 한데 묶어서 관리할 수 있도록 새로운 자료형을 정의한 것이다.
구조체의 정의
구조체의 정의는 다음과 같다
왼쪽은 구조체의 정의를 나타낸 것이다. 오른쪽의 예는 구조체를 정의한 예인데, 20 바이트 문자형 배열과, 4바이트 정수를 저장할 수 있는 변수들로 구성되어 있는 PersonalInfo라는 자료형을 하나 새로 만든 것이다. 이 PerosonalInfo라는 자료형은 int, float, double 등처럼 자료형의 이름이 될 수 있다. 이 이름을 통해서 사용자 정의 자료형 변수를 만들게 되는 것이다.
구조체 변수의 선언과 접근
구조체 변수의 선언
정의한 사용자 정의 자료형(구조체)을 통해 변수를 선언하는 방법은 왼쪽과 같다. 그리고 오른쪽 13번, 14번 라인은 구조체 변수를 선언한 예를 나타내고 있다.
구조체 변수를 통한 멤버 변수 직접 접근과 간접 접근
선언된 구조체 변수를 통해 멤버 변수에 접근할 수 있다. 아니, 해야만 한다. 그러기 위해 만든 구조체이기 때문이다.
왼쪽과 같이 구조체 변수 이름과 ‘ . ‘ (직접 접근 연산자)와 멤버 변수의 이름을 명시함으로써 구조체의 멤버 변수에 직접 접근하여 값을 넣거나 값을 출력 혹은 수정까지 할 수 있다.
위의 예에서는 16번 라인과 17번 라인을 통해 멤버 변수에 접근하고, 대입 및 다른 곳으로의 참조를 시키는 등의 작업이 이루어진다. 중요한 것은 구조체_변수_이름 . 구조체의 멤버 변수 형식을 갖추어 직접 접근한다는 것.
구조체(사용자 정의 자료형) 또한 일반 자료형과 같은 취급을 하기 때문에 포인터로 선언하고 주소 값을 받는 모든 행위들은 허용된다. 다음의 예가 가능하다.
위의 예에서 13번 라인에서 일반 구조체 변수를 선언하고, 15번 라인에서는 구조체 포인터 변수를 선언한다. 그리고 나서 16번, 17번 라인을 통해서 직접 접근 연산자 ‘.’을 이용하여 구조체 멤버에 직접 접근을 통해서 값을 대입한다. 그리고 19번 라인에서 구조체 변수에 기존에 선언했던 일반 구조체 변수의 주소 값을 대입한다. 중요한 것은 21번 라인의 참조 방식인데, ‘->’(간접 접근 연산자)를 통해서 접근하는 형태를 볼 수 있다. 이렇듯 구조체 포인터 변수를 통해서 가리키고 있는 변수의 멤버에 접근할 때에는 간접 접근 연산자(->)를 통해서 접근한다. 이를 간접 접근 이라고 한다.
참조를 통한 직접 접근 또한 가능하다.
22번 라인과 같이 구조체 포인터가 가리키는 대상에 대해서 접근 연산이므로 직접 접근 연산이 맞다. 포인터를 이용해서 참조한 후 직접 접근 연산자를 통해 멤버에 접근할 수 있는 방법이 제시된 예이다.
구조체 변수의 초기화
생성과 동시에 초기화
배열의 초기화와 매우 유사하다.
5번 라인에 해당하는 구조체 정의를 두고, 13번 라인에서 구조체 변수를 선언하면서 생성과 동시에 초기화를 진행하고 있는데 그 초기화 방식은 다음과 같다.
중괄호로 감싼 후, 초기화할 값들을 콤마 연산자를 통해 구분하며 나열하는데 구조체 정의 시 멤버 변수의 선언 순서대로 나열을 한다.
일반 초기화(값의 대입)
다음의 예와 같이 선언 이후에 값의 대입을 통하여 초기화를 진행할 수 있다.
구조체 배열
구조체 배열 또한 일반 변수의 배열과 마찬가지로 다를 바가 없다. 다음은 이전의 예제를 조금 변형한 구조체 배열에 대한 예제이다.
먼저, 15번 라인에서 구조체 배열을 선언한다. 두 명의 학적 정보를 저장할 수 있도록 배열로 선언한다. 그런데 배열을 선언과 동시에 초기화를 이루고 있다. 이 경우 2차원 배열의 초기화와 크게 다를 바가 없다. 구조체 정의 시 나열한 멤버 변수의 순서대로 값들을 나열하고, 그러한 나열을 행 별로 다시 구분 지어 나열한다. 그리고 20번 라인에서는 선언만 이루어졌고, 22번 ~ 26번 라인에서 대입을 통한 초기화가 이루어지고 있다. 그리고 29번 라인부터는 인덱스를 이용하여 구조체 배열의 각 요소들을 출력하는 것을 볼 수 있다.
구조체 포인터 및 구조체 첫 멤버 변수의 주소 / 구조체 변수의 주소 / 구조체 이름
구조체 포인터 또한 일반 변수의 포인터와 다를 바가 없다. 다만 다른 부분은 아래에 제시한다.
위의 결과로 미루어 보았을 때 구조체의 첫 멤버 변수의 주소와 구조체 변수의 주소는 같지만 구조체 이름은 다른 것임을 알 수 있다. (배열 이름과는 다름)
l구조체와 typedef 연산을 통한 자료형 재정의
Typedef 는 자료형을 다른 이름으로 재정의하는 연산자이다. 다음과 같은 형식으로 재정의를 진행한다.
typedef 기존_자료형 새로운_자료형_이름;
다음은 기존 자료형을 통한 자료형 재정의의 예이다.
11번, 12번 라인에서 int 자료형과 char 자료형에 대해서 새로운 이름으로 재정의가 일어났다.
다음으로는 사용자 정의 자료형에 대해서 typedef 연산을 통해 재정의가 일어난 몇 가지 경우를 표현했다. 아래에서 제시하는 모든 경우에 대한 결과는 다음과 같다.
14번 라인과 같이, 일반 자료형을 통한 변수 선언 하듯, struct 키워드를 포함하지 않더라도 구조체 변수의 선언이 가능하다. 밑에서 11번 라인에 들어가는 다양한 경우의 typedef 선언을 제시.
함수 구조체 인자 전달
구조체를 대상으로 가능한 연산
구조체 변수를 대상으로 하는 연산은 제한적으로 대입(=), sizeof, 주소(&) 연산만이 허용된다. 특히 구조체의 변수 간 대입 연산을 진행하게 되면 멤버 대 멤버의 복사가 이루어진다.
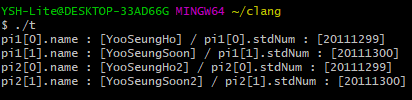
15번 라인에서 대입 연산을 진행하고 있고 그 결과, pi1과 pi2의 멤버들이 지니는 값은 모두 같은 것으로 미루어 보았을 때, 값의 복사가 이루어지고 배열의 경우에도 모조리 값의 복사가 일어나는 것을 확인할 수 있다.
구조체의 정의 이유와 중첩된 구조체의 선언
구조체의 정의가 필요한 이유
구조체를 통해서 연관 있는 데이터를 하나로 묶을 수 있는 자료형을 정의하면, 데이터의 표현 및 관리가 용이해지고, 합리적인 코드를 작성할 수 있다.
구조체를 정의하지 않고 구현한 경우 문제가 되는 점 : 인자 전달 시 매개 변수가 늘어남, 묶어서 하나의 인덱스에 대해서 관리가 불편해짐. 높은 차원의 배열이 계속 생성됨. 등
중첩된 구조체의 정의와 변수 선언
구조체 내에 구조체 변수를 선언할 수 있다. 이때 초기화 할 경우에는 순서에 주의하고, 중첩된 구조체 변수에 대한 초기화 시 중괄호를 통해 구분한다.
공용체(union)
공용체는 구조체와 유사한 개념이긴 하나, 다른 점은 멤버 변수들이 하나의 공간을 공유하는지의 차이가 있다.
위의 예제는 구조체와 공용체의 차이를 나타내는 예제이다. 공용체의 정의나 선언 방법은 구조체와 완전히 똑같다고 보면 된다. 그러나 차이는 24번 ~ 28번 라인에서 볼 수 있다.
24번 라인에서는 구조체의 멤버의 각 주소 값을 출력하는데 결과를 보면 자료형 별 차이만큼 주소 값이 잘 할당되어 있는 것을 확인할 수 있는데 25번 라인에서 공용체의 멤버의 각 주소를 출력하는데 결과를 보니 모두 같은 주소(공용체의 시작 주소) 값을 가지고 있었다. 게다가 이상한 것은 이 뿐만이 아니다. 27번 라인에서 sData의 크기는 멤버 변수들의 메모리 공간 할당 크기들을 합한 결과 값이 나오는데, uData의 크기는 멤버 변수 중 가장 할당 크기가 큰 자료형의 길이 값이 나왔다.
< 구조체 멤버 변수의 할당 구성 >< 공용체 멤버 변수의 할당 구성 >
위의 그림은 구조체와 공용체의 멤버 변수들의 할당 구성을 나타낸 것이다. 굵은 검정 칸이 실제로 할당된 메모리 공간이 된다. 구조체 할당 구성에서는 각 멤버 변수 별로 크기만큼 할당이 되어 있는 것을 볼 수 있는데 공용체 할당 구성에서는 가장 큰 double 자료형의 크기만큼만 공간을 할당하고 모든 멤버 변수가 이 공간을 공유하는 형태로 할당 구성이 이루어진다.
이러한 공용체는 다음과 같은 예제에서 유용하게 사용될 수 있다.
정수 하나를 입력 받고, 입력 받은 정수의 상위 2바이트와 하위 2바이트의 값을 양의 정수로 출력하고, 상위 1바이트와 하위 1바이트에 저장된 아스키 문자 출력하기
열거형
구조체나 공용체는 자료형을 명시함으로써 멤버에 저장할 값의 유형(type)을 결정하였다면, 열거형의 경우는 저장이 가능한 값 자체를 정수의 형태로 결정한다.
0, 1, 2, 3, 4, 5, 6 값들을 저장 가능한 color형 자료형
Color 자료형으로 선언되는 모든 변수들은 enum Color 정의에서 정의해 둔 상수들을 값으로 갖을 수 있다. 또한 정의된 상수들은 어디서든 지역 범위를 고려하여 사용할 수 있다. enum 정의 및 변수 선언은 구조체, 공용체와 완전히 똑같다. 그리고 상수 정의 시, 어떤 값도 넣지 않으면 순서대로 0 값부터 값이 1씩 올라가는 형태로 값의 배정이 이루어진다.
다음의 예에서 특이한 점을 발견할 수 있다.
위에서는 정의된 상수들에서 RED에 값을 지정하지 않았으므로 0부터 시작하는데 YELLOW는 10이라는 값을 지정했다. 그리고 그 결과 YELLOW 이후 부터는 10부터 1씩 증가한 값들로 배정된다.
열거형은 위와 같이 활용될 수 있다.
열거형의 유용함은 이름있는 상수의 정의를 통한 의미의 부여에 있다. 둘 이상의 연관이 있는 이름을 상수로 함께 같이 묶어서 선언함으로써 프로그램의 가독성을 높인다.
프로그램과 입력 및 출력 장치를 연결해주는 소프트웨어적으로 구현되어 있는 도구, 입출력 장치와 프로그램을 연결해주는 가상의 다리이다. 운영체제가 이를 제공한다.
문자 단위 입/출력 함수
EOF란 End Of File의 약자로 파일의 끝을 표현하기 위해 정의된 상수이다. 위의 함수가 파일이나 콘솔의 출력으로 EOF를 반환하게 되면 파일이나 콘솔로부터 더 이상 입력 받을 것이 없다 라는 의미를 갖는다. 그렇다면 EOF를 반환하는 시기는 다음과 같다.
함수 호출의 실패할 경우 컨트롤 + z / 컨트롤 + d 키가 입력될 경우
문자를 입력 받는 함수인데 반환 형이 정수 int 형인 이유는? 컴파일러에 따라 char을 unsigned char로 처리하는 경우가 존재한다. 그런데 EOF 라는 값은 -1로 정의되어 있는데 char을 unsigned char로 처리하는 컴파일러는 EOF에 대한 처리가 불가능하다. 그렇기 때문에 같은 정수 타입인 int로 반환한다.
문자열 단위 입/출력 함수
기존의 scanf 함수 등은 공백을 포함한 문자열을 입력 받기에 있어서 크게 제한이 되었다. (공백을 기준으로 입력을 나누기 때문)
표준 입/출력 버퍼
표준 입/출력 함수를 통해서 데이터를 입/출력하는 경우, 해당 데이터들은 운영체제가 제공하는 메모리 버퍼를 꼭 통과하게 되어 있다. 메모리 버퍼는 데이터를 임시로 저장해 놓는 메모리 공간인데, 이런 저장하는 작업을 버퍼링 이라고 한다.
키보드로 데이터를 입력하면(문자열 입력 후 엔터를 칠 경우) 해당 데이터들은 입력 버퍼로 전송되어 저장되고(버퍼링), 그 이후에 프로그램으로 데이터들이 전송이 된다.
버퍼링을 하는 이유?
프로그램 연산(CPU 연산)에 비했을 때 I/O 장치들 과의 I/O 작업은 상당히 시간이 걸리는 작업이다. 즉, 데이터를 읽어오는데 걸리는 시간이 CPU의 연산 처리 속도보다 훨씬 느리다. 그렇기 때문에 CPU는 그러한 느린 데이터 입출력 처리를 기다리고 있어야 하는데 데이터를 읽을 때마다 조금씩 전송을 하는 구조로 진행되면 데이터 전송의 효율성이 떨어진다. 그렇기 때문에 중간에 메모리 버퍼를 두고 데이터를 한데 묶어서 보내면 빠르고 효율적인 데이터 전송이 될 수 있다.
출력 버퍼와 입력 버퍼 비우기!
출력 버퍼를 비운다는 것은 출력 버퍼에 저장된 데이터가 버퍼를 떠나서 목적지로 이동되는 것을 이야기하는데, 이러한 역할을 하는 함수가 존재하는데 다음과 같다.
위 함수는 파일을 대상으로도 버퍼 비우기가 가능하고, 출력 버퍼를 비우는 일은 많이 존재하지는 않는다.
반면에, 입력 버퍼를 비운다는 것은 출력 버퍼와는 다르게 데이터의 소멸을 의미한다. fflush 함수를 이용하여fflush(stdin); 과 같은 형태로 호출하면 입력 버퍼는 비워지거나/비워지지 않거나 보장할 수 없는 결과를 나타낸다. (Windows 계열의 컴파일러의 경우는 입력 버퍼를 지워 준다고 한다.)
입력 버퍼를 비우기 이전에 입력 버퍼를 비워야 하는 경우에 대한 예제이다.
먼저, 6번 라인에서 str1의 크기를 10 바이트로 지정해주었고, 10번 라인에서 str1에 문자열을 대입하는데 9자리의 문자를 대입한다. 9자리라고 함은 문자열 9자리와 NULL 문자 1바이트를 고려한 것이다. 그러나 입력될 때에는 “abcdefghi\0\n” 이 입력되고 입력 버퍼에 들어가게 된다. (fgets함수의 ‘\n’이 입력될 때까지 읽어 들이는 특성 상) 그래서 10번 라인에서는 입력한 “abcdefghi” 문자열에 ‘\0’ 문자가 합쳐져서 입력으로 str1에 저장된다. 그리고 13번 라인에서 fgets 함수가 호출되는데 이 때 입력 버퍼에 남은 ‘\n’ 문자를 읽어버리고 바로 호출이 끝나게 된다. 그렇기 때문에 실행 결과에서는 str2에 ‘\n’만 저장된 결과가 나타난 것이다. 이러한 경우 str1의 저장 이후 입력 버퍼를 비웠더라면 다음 문자열 입력을 받을 수 있었다. 이것이 입력 버퍼 비우기의 필요성이다.
입력 버퍼를 비운다는 것은 문자들을 읽어 들이면 지워진다, 즉 비워진다. 다음과 같은 함수로 입력 버퍼를 지울 수 있다.
23번 라인에서 한 문자씩 읽는데 그 읽은 것이 ‘\n’ 개행 문자일 경우 탈출하게 된다. 즉, 개행 문자까지 버퍼로부터 문자를 읽음으로써 버퍼가 비워진다.
문자열의 길이를 반환 : strlen
일단, size_t는 typedef unsigned int size_t; 로 자료형 재정의가 되어 있다.
문자열의 복사 : strcpy
strcpy는 src의 문자열을 dest에 복사한다. strncpy의 경우에는 src의 문자열을 dest에 복사하되, n 크기만큼 복사한다. 단, strncpy의 경우 마지막 문자가 NULL인지에 대한 검사는 하지 않고 주어진 n만큼만 복사를 한다. 즉, 복사된 문자열의 끝에서 NULL에 대한 처리를 진행하지 않기 때문에 직접 NULL 처리를 해줘야 한다. 이후에 기재되는 모든 n이 들어가는 함수는 NULL처리가 진행되지 않는 공통점을 가지고 있다.
문자열 연결 : strcat
Dest 문자열 뒤에 src 문자열을 붙이고 그 값을 dest에 저장한다. 앞 문자열의 NULL 문자를 없애고 그 자리부터 뒷 문자열이 시작된다.
함수 또한 메모리 상에 바이너리 형태로 올라가 호출 시 실행이 되는데, 메모리 상에 저장된 함수의 주소 값을 저장하는 포인터 변수가 함수 포인터 변수이다.
배열의 이름이 배열의 시작 주소 값을 의미하듯이 함수의 이름 또한 함수가 저장된 메모리 공간의 시작 주소 값을 의미한다.
함수 이름의 포인터 형은 반환 타입과 매개변수의 선언을 통해 결정 짓도록 약속. 즉, 반환 타입과 매개변수의 선언이 일치하는 모든 함수들의 포인터 형은 모두 같다.
9번 라인과 10번 라인에서 볼 수 있듯이
반환 타입 (*포인터변수이름) (매개 변수) = 함수 이름
다음과 같은 형태로 함수 포인터 변수를 선언하고 함수의 주소를 받아서 12번, 13번 라인처럼 함수 포인터 변수를 통한 함수 호출이 가능하다.
Void 형 포인터 ( 자료 형이 없는 포인터 )
다음과 같이 선언되는 포인터를 void 형 포인터 변수라고 한다.
Void 형 포인터는 어떤 변수의 주소 값이든 함수의 주소 값이든 상관 없이 ‘주소’ 값의 경우는 무엇이든 전부 담을 수 있다. 다음 예는 void * 변수에 다양한 주소 값을 저장하는 예를 나타낸 것이다.
단, void 형 포인터 p를 이용하여 참조를 하는 순간(=포인터 연산을 하는 순간) 컴파일 에러가 발생한다. 왜냐하면 void * 포인터는 포인터 연산 시 증감의 크기에 대한 정보가 단 한 부분도 없다. 즉, 해당 주소로부터 어느 범위까지 연산을 하여 참조를 해야하는지에 대한 정보가 없기 때문에 참조(포인터 연산)가 불가능하다.
void형 포인터는 주소 값을 저장하는 것에만 의미를 두고 포인터 형은 나중에 결정한 참조하는 경우에 유용하게 사용된다 ->동적 메모리 할당
Main 함수를 통한 인자 전달
위의 예제에서 argc는 파일 이름을 포함한 전달 되어온 인자의 수를 나타내고, argv는 더블 포인터 형태로 싱글 포인터 혹은 싱글 포인터 배열의 각 요소를 가리킨다. 즉, argv는 두 번째 결과에서 “./t”, “yoo”, “seung”, “ho”의 주소 값인 char * 타입을 가리키기 때문에 더블 포인터 형태이다.
먼저, 기본적으로 함수에서 인자를 전달할 때는 값의 복사 방법으로 인자가 매개변수로 전달이 된다.
위의 예제에서 num 변수를 func 함수의 인자로 넣어 값을 전달하는데 이 때 전달되는 것은 num 변수가 아니라 num 변수의 값이 전달되어 arg 변수에 저장된 것이다. 결국, 지역 변수 num과 함수의 매개 변수 arg는 서로 전혀 관련 없는 별개의 변수이다. ( arg 매개 변수 값을 아무리 변경하더라도 num 지역 변수의 값의 변화는 일어나지 않는다. )
배열을 함수의 인자로 전달하는 방법
배열을 기본 인자 전달 방법인 값의 복사 방법으로 통째로 복사하여 전달하는 방법은 존재하지 않는다.
위와 같은 소스는 컴파일 가능하지 않다. 왜냐하면 매개 변수로 배열을 선언하는 것은 허용되지 않기 때문이다. 그러나 gcc 컴파일러 6.4.0 version을 기준으로 위의 소스가 실행이 되고 정확한 결과가 나와서 가능한 것처럼 보였으나,
위와 같이 지역 변수의 배열과 매개 변수의 배열의 배열 이름의 값을 출력해 보았다. 그 결과는 다음과 같다.
두 배열 이름이 같은 주소를 지니고 있다. 이 뜻은 지역 변수의 배열 arr는 문제 없이 정상적인 방법으로 메모리 할당이 이루어져 배열을 이루고 있는 것이지만, 매개 변수의 배열 arg는 외형과 다르게 포인터 변수로서 선언되어 있다.
포인터 변수이기 때문에 arg의 값의 변경이 가능하다. 그리고 다음은 그 결과이다.
아파트를 보고 싶어 하는 사람 앞에 아파트를 통째로 복사해 놓을 수 없다면, 아파트를 직접 찾아가도록 주소를 알려주듯이 배열을 통째로 복사가 불가능하다면 배열의 시작 주소 값을 전달하고, 그에 맞는 포인터 형을 매개 변수를 이용하여 포인터 연산으로 각각의 배열 요소에 접근하여 원하는 값을 참조하면 된다.
18번 라인에서 넘겨주는 배열 이름(배열의 시작 주소)을 5번 라인에서 포인터 변수를 통하여 받고 포인터 연산을 통하여 ( arg[i] = *(arg+i) ) 각각의 요소를 참조하여 출력을 한다. 매개 변수 한정으로 5번 라인에서 주석 친 부분과 같은 형식으로 매개 변수를 선언하고 주소를 받을 수 있다.
Call by value 그리고 Call by reference
두 방법에 대해 정리하기 이전에 두 변수의 값을 서로 교환하는 “SWAP” 문제에 대해서 두 방법을 적용해보고 해결하는 과정으로 두 방법을 정리할 것임.
먼저 call by value이다. 이 방법은 함수 인자 전달의 기본 방식이다.
swap 함수 내에서는 값이 변경되었으나, 정작 바뀌어야 할 main 함수 내의 변수들은 swap이 이루어지지 않았다 이는 복사에 의한 인자 전달이기 때문에 변경이 되지 않는 것은 당연한 일이다. 변경된 것은 swap 함수 내의 매개 변수끼리 값이 변경된 것이다. 이러한 swap은 진정한 의미의 swap이라고 할 수 없다. 이를 해결하기 위해선 주소가 주어지고 해당 주소를 직접 참조하여 값을 변경하는 방식으로 전개를 해야 한다.
다음은 call by reference이다.
주소를 전달하고, 전달된 주소를 참조하여 값을 변경하는 방법으로 값이 성공적으로 swap 되었음을 확인할 수 있다. scanf 함수 또한 call by reference 방법으로 인자를 전달하는 형태이고, 문자열(%s)을 입력 받을 때 ‘&’ 를 붙이지 않는 이유와 그 외의 값을 받을 때 ‘&’ 를 붙이는 이유를 call by reference 방법으로부터 알아낼 수 있다.
포인터에서의 const 키워드
다음과 같은 변수가 선언되어 있는 상황이다.
이러한 상황에서 const 키워드를 어느 위치에 사용하는지에 따른 결과들을 분석할 것.
1.포인터 변수가 참조하는 대상을 상수화(const 화)한다.
포인터 변수 p를 통하여 number의 값이 변경되는 것을 허용하지 않는다.
2.포인터 변수를 상수화(const 화)한다.
포인터 변수 p를 상수화 하여 포인터 변수 p의 값이 변경되는 것을 허용하지 않는다.
3.둘 다 상수화(const 화)한다.
p를 통한 number의 값의 변경, p의 값 변경 모두 허용하지 않는다.
4.일반 변수를 상수화(const 화) 한다.
변수 n을 상수화 하여 n의 값을 변경할 수 없다.
Const 키워드는 C++에서만 제공했던 키워드, 표준을 재정립하는 과정에서 C언어서도 지원을 해준다. Const 키워드는 값이 바뀌어서는 안 되는 변수의 변경을 막아준다. 이러한 경우는 프로그램을 실행하는데 있어서는 치명적인 오류로 작용할 수 있지만 문법 상으로는 문제가 없기 때문에 컴파일 오류 하나 받아볼 수 없다. 그렇기 때문에 효율적이고 현명한 프로그램을 원한다면 const 키워드를 자주 사용하는 습관을 들여놓아야 함.
위의 소스에서 확인할 수 있는 부분은 배열의 이름 그 자체를 출력했을 때의 값과 배열의 [0]번째 요소의 주소 값이 같다는 점이다. 즉, 배열의 이름은 해당 배열의 시작 주소 값을 의미한다.
결국 배열의 이름 또한 ‘주소 값’을 지니고 있다는 관점에서 포인터와 그 개념이 매우 유사하다. 그렇다면 포인터 변수처럼 배열의 이름 또한 주소를 대입해볼 수 없을까? 배열의 이름에 주소 값을 대입하는 예제이다.
8번 라인에 새로운 변수 number를 선언하고, 10번 라인에서 배열의 이름에 number의 주소 값을 넣었다. 왜 배열의 주소가 아니라 일반 변수의 주소를 넣었느냐? 왜냐하면 배열의 이름은 배열의 ‘시작 주소’ 하나를 저장하기 때문에 배열 이름의 입장에서 보면 어떤 하나의 변수의 주소 값을 대입한 것과 다를 바 없이 보이기 때문이다. 그렇기 때문에 배열의 이름에 하나의 변수 number의 주소 값이 대입되는 것은 문제가 되지 않는다. 이렇게 배열의 이름에 변수의 주소를 넣은 결과, 10번 라인에서 배열 타입의 표현 식에 할당하는 부분에서 에러가 발생한다. 그 이유는 배열의 이름은 주소 값을 저장하고 가리키지만 처음 정해진 배열 이름의 값은 변경이 불가능하다. 즉, 배열의 이름은 상수 값이다.그도 그럴 것이 특별하게 배열을 선언하여 만들었는데 그 배열의 이름을 대표하는 배열의 이름이 가리키는 요소를 마음대로 바꾸게 되면 무엇을 위해 배열 이름을 지정해가며 배열을 생성했겠는가?
다음은 위에서 배열과 포인터의 관계에 대해 내린 결론을 정리하여 나타낸 표이다.
배열 이름은 포인터 변수와 같은 특성들을 지니고 있지만 상수라는 차이점이 있다. 그래서 배열 이름을 ‘포인터 상수’ 라고도 표현한다. 포인터 변수와 배열 이름은 변수이냐, 상수이냐 의 차이점 밖에 없기 때문에 그 차이를 제외하면 포인터 변수와 배열 이름은 완전히 같다. 그렇기 때문에 다음의 예제가 가능하다.
10번 라인에서 배열 이름(포인터 상수)의 값을 포인터 변수에 대입시키고 있다. 이것이 가능한 이유는
1.포인터 변수에 포인터 상수를 대입 -> 전혀 문제될 것이 없다.
2.대입 연산자를 기준으로 l-value와 r-value의 형(type)이 같아야 한다. -> l-value : int * / r-value : int * == int형 (시작) 주소 로 문제될 것이 없다.
배열 이름의 포인터 형은 배열의 이름이 가리키는 대상을 기준으로 결정되기 때문에 r-value 배열 이름의 자료형은 정수형 변수 공간의 시작 주소이므로 int * 가 맞다.
포인터 변수에 포인터 상수를 대입하게 되면 포인터 변수를 이용하여 배열 이름처럼 인덱스로써 접근하는 방법으로 각 요소에 접근을 할 수 있다. 즉, 포인터 변수를 배열의 이름처럼 사용할 수 있다는 것이 결론.
그렇다면 그 반대로 배열 이름(포인터 상수)을 가지고 포인터 연산을 할 수 있을까? 다음은 이에 관한 예제이다.
11번 라인에서 배열 이름과 ‘ * ‘, 애스터리스크 연산자를 이용한 포인터 연산이 진행되고, 12번 라인에서는 배열 이름과 인덱스를 이용한 배열의 0번째 요소에 접근하여 출력을 한다. 11번 라인에서는 배열 이름이 가지고 있는 값 즉, 배열의 시작 주소에 접근하여 해당 값을 출력하기 때문에 0번째 요소를 출력한다.
포인터 연산
포인터를 이용하여 참조 뿐만 아니라 증감 연산이 가능하다. 다만 일반 수를 이용한 연산에 비해서 연산이 많이 제한 된다.-> 가능한 연산자 수의 제한
포인터 연산에서 중요한 포인트
1.덧셈, 뺄셈, 참조 연산만 가능하다. -> 곱셈, 나눗셈 등의 연산을 불가능하다.
2.덧셈, 뺄셈 연산은 일반 수를 통한 덧셈, 뺄셈 연산과는 다르다. -> 포인터 연산에서의 +1과 수에 대한 +1에서 1은 각각 의미가 다르다.
다음은 포인터에 + 연산자를 이용하여 1씩 더하는 예제이다.
int, char, double 자료형 별로 배열을 선언하고, 각각에 대한 포인터 변수를 선언하여 각 배열의 첫 시작 주소(배열 이름)를 대입시킨 상황에서 각각 포인터 연산을 진행하는 예제이다.
먼저, 자료형에 상관없이 배열 이름과 인덱스를 이용하여 요소별 주소 값을 출력한 결과와 포인터 연산에 대한 결과를 출력한 결과가 모두 동일함을 알 수 있다. 그렇다면 도대체 + 연산자를 이용하여 포인터 변수를 포인터 연산한 것이 어떤 의미가 있길래 각 요소의 주소를 출력한 결과와 같은 결과인가?
1.A의 결과에서 pArr과 pArr+1 값의 차이는 4이다.
2.B의 결과에서 pCrr과 pCrr+1 값의 차이는 1이다.
3.C의 결과에서 pDrr과 pDrr+1 값의 차이는 8이다.
단순히 포인터 변수에 +1 연산을 했을 뿐인데 그 증가의 차이는 자료형 별로 다른 결과가 나타났다. 포인터 연산은 피연산자로 오는 그 대상이 메모리 주소인 만큼 메모리 주소에 대한 연산이 이루어지는데 이 메모리는 무작정 작은 단위인 1바이트 별로 보는 것은 의미가 없다. int 형의 경우에는 4바이트 전부 참조해야 비로소 값이 의미가 있듯이 자료형 별로 최소 참조 바이트가 존재한다. 그렇기 때문에 주소에 대한 연산인 포인터 연산은 자료형 별 최소 참조 바이트를 반영하여 증감을 진행한다. 각 자료형 별로 포인터 연산에 대해서 1의 의미가 모두 다른 이유가 바로 이 때문이다. 1의 증감은 최소 참조 바이트 한 블록을 증감한다는 의미가 되기 때문이다.
포인터 연산에서 1의 의미는 sizeof(해당 자료형)*1 이 된다. 포인터 연산에서 2의 의미는 sizeof(해당 자료형)*2 이 된다. … 포인터 연산에서 n의 의미는 sizeof(해당 자료형)*n 이 된다.
그렇다면 다음의 예는 무엇을 의미하는가?
*(p + 1) p는 임의의 변수를 가리키고 있는 포인터 변수
이는 다음과 같이 해석할 수 있다.
P가 가리키고 있는 주소에 sizeof(해당 자료형) * 1만큼을 더한 주소를 참조(*)한다.
다음은 그 예제이다.
위와 같은 포인터 연산에서의 성질과 예제를 통해서 알 수 있는 결론은 다음과 같다.
배열 이름[i] == *(배열 이름 + i) 혹은 포인터 변수[i] == *(포인터 변수 + i)
완전히 같다.
문자열과 포인터
c언어에서 문자열을 표현할 때 두 가지 방법으로 표현한다.
1.배열을 통한 문자열의 저장
2.포인터 변수를 통한 문자열의 저장
먼저, 첫 번째 방법인 배열을 통한 문자열의 저장이다. 이 경우에는 str 배열의 길이가 자동 계산되어 각 인덱스 별로 문자를 하나씩 저장하여 해당 문자열의 끝에 ‘\0’을 저장함으로써 문자열의 저장이 비로소 완료되는 형태이다.
그러나 두 번째 방법인 포인터 변수를 통한 문자열의 저장의 경우이다. c언어 프로그램 상의 모든 상수는 CPU를 이용한 연산의 대상이 되기 위해서는 해당 상수가 메모리 상에 적재되어야 한다. “hello, my name is yoo seung ho!” 문자열은 상수로서 메모리에 적재되고, 그 시작 주소인 ‘h’의 주소 값이 반환되어 pStr 포인터 변수에 대입이 된다.
대입 연산자를 기준으로 l-value는 char * 형이고, r-value는 문자열의 시작 주소 값 즉, char * 이기 때문에 대입 연산에는 아무런 문제가 없다.
각 두 경우는 위 그림의 왼쪽과 오른쪽 형태로 동작한다. 배열의 이름의 경우 포인터 상수이기 때문에 가리키는 타겟 문자열을 변경할 수는 없지만, 변수 형태, 배열에 값이 저장되어 있기 때문에 대상이 되는 문자열의 내용에 대해서는 변경이 가능하다. 포인터의 경우 포인터 변수이기 때문에 가리키는 타겟 문자열을 변경할 수 있다. 그러나 그 대상은 상수 형태의 문자열이기 때문에 대상이 되는 문자열의 내용에 대해서는 변경이 불가능하다.
배열의 인덱스는 배열의 개수를 [n] 으로 두었을 때, 0부터 시작하여 n-1까지 존재하며 [0]은 첫 번째 요소를, [n-1]은 마지막 요소를 나타낸다.
배열의 선언과 동시에 초기화
다음은 배열의 선언과 동시에 초기화하는 예이다.
여기에서 우리는 중괄호 내의 초기화 값 리스트를 ‘초기화 리스트’ 라 부른다. 8번 라인의 경우에는 일반적인 선언과 동시의 초기화 방법이다. 9번 라인의 경우는 배열의 길이 정보가 주어지지 않은 상태인데 이는 초기화 리스트를 보고 자동으로 계산하여 배열의 길이가 세팅 된다. (위의 예에서는 5) 마지막으로 10번 라인의 경우는 배열의 길이보다 적은 초기화 리스트가 오게 되는데 0번째 인덱스부터 순차적으로 초기화 리스트의 값들이 할당되고 할당할 초기화 값이 없는 인덱스 요소에 대해서는 전부 0으로 자동 초기화한다.
배열 이름을 대상으로 하는 sizeof 연산자
sizeof(배열이름); 을 실행할 경우, ‘ 바이트 단위의 배열의 크기 ’가 반환된다.
문자 배열과 문자열 배열
같은 ‘ hello ‘를 표현하는 배열인데 두 배열은 전혀 다른 배열이다. 9번 라인은 문자만을 저장한 문자 배열이고, 12번 라인은 문자열을 저장한 문자열 배열이다. c언어에서 배열에 문자열을 저장할 때에는 ‘\0’ 이라는 문자열의 끝을 나타내는 특수 문자인 널(null) 문자를 문자열의 제일 끝에 자동으로 삽입하여 대입 및 저장을 행한다. ( 이는 문자열을 입력 받는 라이브러리를 통한 변수로의 입력 시에도 마찬가지로 null 문자의 자동 삽입이 이루어진다. ) 이 null문자를 이용하여 메모리 공간 상에서 배열 이름의 첫 번지부터 어디 까지가 의미 있는 문자열의 끝인지를 확인한다. 또한 이러한 문자열 배열에 대한 입출력 서식 문자는 ‘ %s ‘ 로 사용한다.