C기반 I/O Multithreading - 14. 쓰레드의 치명적인 문제점
C기반 I/O MultiThreading - 12. 멀티 프로세싱? 멀티 쓰레딩? 멀티 프로세싱에 이어서, 멀티 프로세싱의 단점이 보완되는 멀티 쓰레딩 개념이다. 사실 단점이 보완되기는 하는데 함께 딸려오는 문제 거
typingdog.tistory.com
이 포스팅에서는 멀티 쓰레드 기반의 병렬 처리에서 발생하는 임계 영역과 관련된 문제를 해결하기 위한 방법이다. 위는 그 문제점에 대해서 다루었던 포스팅이다.
멀티 쓰레드 기반의 병렬 처리에서 임계 영역과 관련된 문제를 해결하기 위한 방법으로는
뮤텍스
세마포어
등이 존재한다. 이 방법들은 쓰레드 동기화라고 하는데, 쓰레드의 접근 순서로 인해 발생하는 문제를 해결하기 위한 순서의 동기화를 의미한다.
이름부터 무슨 세포 이름 같기도 하고, 이상한 인상을 받았다. 그러나 잠시 후에는 진짜 개쩌는 놈들이라는 것을 알게 될 것이다. 작성자는 깔끔하게 문제가 해결되는 것을 보고 감탄을 했었다ㅋㅋㅋㅋ ㄹㅇ
Mutex, 뮤텍스
먼저, 뮤텍스이다. Mutual Exclusion의 줄임말로.

역시나 쓰레드끼리 공유하는 변수에 동시 접근을 막는 의미로 사용된다. 이걸 정말 어떻게 기록해야할까 고민을 많이 했는데 코드와 함께 비유를 섞어서 하는게 났겠다 싶다.
뮤텍스는 임계 영역을 대상으로 문을 하나 포함한 벽과, 열쇠를 만드는 것으로 비유하면 될 것이다.
이 벽으로 둘러 쌓인 임계 영역에는 딱 한 사람만(하나의 쓰레드 실행 흐름만) 들어갈 수 있으며, 들어갈 때는 꼭 열쇠로 문을 잠그고 나올 때는 열쇠로 문을 열어 놓고 나간다.
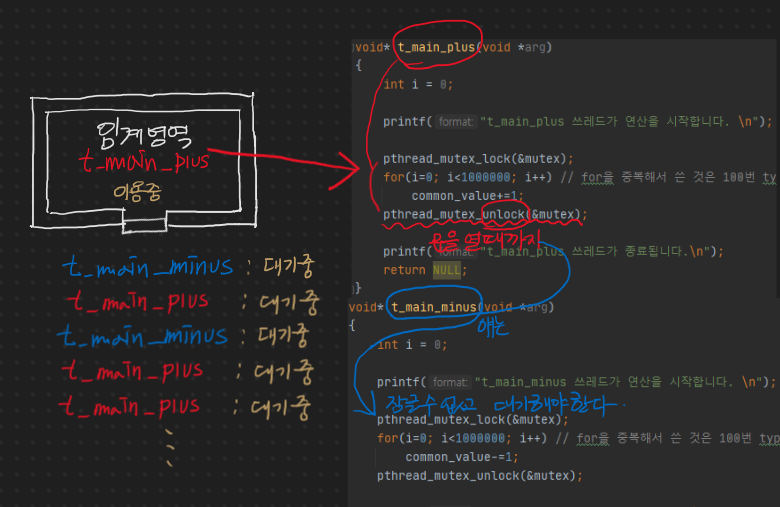
근데 이상한 점이 있다. 그림으로만 보면 임계영역이라는 것은 하나인데, t_main_plus 함수와 t_main_minus 함수내에서 서로 다른 코드 영역이다.
좀 더 정확히 말하자면 벽과 열쇠를 가져다가 사용할 수 있는 권한을 lock과 unlock을 통해 얻고 문을 열고 닫는 것이라고 생각하면 될 것 같다. "쓰레드가 각자 임계 영역에서 계산 및 작업을 할 것인데 벽과 열쇠로 둘러쌓지 않으면 작업을 못한다"라고 규정해버리면 자연스럽게 대기를 할 것이다.
그런데 서로 다른 라인의 코드 영역이긴 하지만, 결국에는 접근하여 조작하는 변수는 같기 때문에 그림으로는 하나의 영역에 들어가는 것처럼 표현한 것이다. 조금 유연하게 이해를 해야할 필요가 있는 것 같다.. 아니면 조금 더 코드의 레벨로..?
아무튼 그래서 뮤텍스 관련 함수를 한 번에 기록하겠다. 별로 필요로 하는 인자가 없기 때문에 간단하게 정리한다.

이어서 간단한 예제를 확인하겠다. 지난 예제의 보완이다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
|
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <pthread.h>
pthread_mutex_t mutex;
int common_value = 0;
void* t_main_plus(void *arg);
void* t_main_minus(void *arg);
int main(void)
{
pthread_t tid1, tid2;
pthread_mutex_init(&mutex, NULL);
pthread_create(&tid1, NULL, t_main_plus, NULL); // 쓰레드 생성
pthread_create(&tid2, NULL, t_main_minus, NULL); // 쓰레드 생성
pthread_detach(tid1); // tid1 에 해당하는 쓰레드가 종료됨과 동시에 소멸.
pthread_detach(tid2); // tid2 에 해당하는 쓰레드가 종료됨과 동시에 소멸.
sleep(7); // 종료되지 않도록 대기.
pthread_mutex_destroy(&mutex);
printf("메인함수가 종료됩니다. [common_value의 최종 값 : %d]\n",common_value);
return 0;
}
void* t_main_plus(void *arg)
{
int i = 0;
printf("t_main_plus 쓰레드가 연산을 시작합니다. \n");
pthread_mutex_lock(&mutex);
for(i=0; i<1000000; i++) // for을 중복해서 쓴 것은 100번 type을 검사하는 것보단 났다고 생각.
common_value+=1;
pthread_mutex_unlock(&mutex);
printf("t_main_plus 쓰레드가 종료됩니다.\n");
return NULL;
}
void* t_main_minus(void *arg)
{
int i = 0;
printf("t_main_minus 쓰레드가 연산을 시작합니다. \n");
pthread_mutex_lock(&mutex);
for(i=0; i<1000000; i++) // for을 중복해서 쓴 것은 100번 type을 검사하는 것보단 났다고 생각.
common_value-=1;
pthread_mutex_unlock(&mutex);
printf("t_main_minus 쓰레드가 종료됩니다.\n");
return NULL;
}
|
cs |
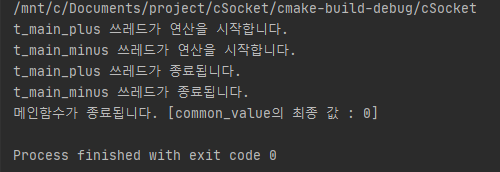
몇 번을 실행해도 백만씩 더하고, 빼기가 정확하게 이루어져 0을 이루는 모습이다. ㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷ
교착 상태, 데드락
이렇게 lock / unlock 기법을 사용하는 곳에 꼭 동반하는 문제가 무어냐면 교착 상태라는 데드락 상태이다.
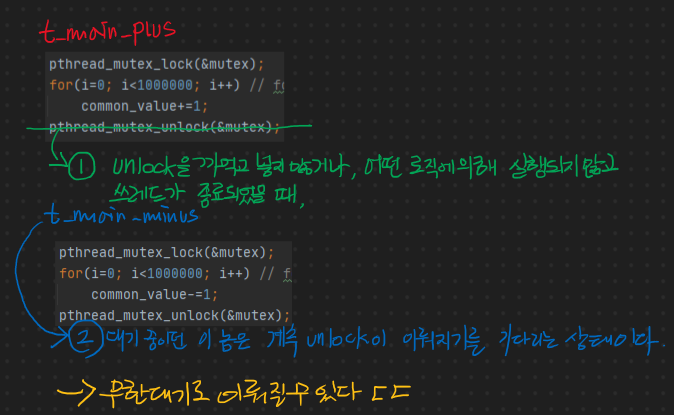
그림의 숫자 순서대로 읽으면 되고, 이를 꼭 주의해야 한다. 1번의 경우는 생각보다 잘 나올 수 있다. lock을 건 쓰레드가 뻑이나거나 사망해버릴 경우 문이 잠긴 채로 unlock이 호출되지 않고 교착 상태에 들어가는데 이런 경우는 답이 없다 ㅋㅋㅋㅋ 디비에서도 그렇고 운영체제에서도 그렇고 비슷한 일들이 일어난다.
다음은 세마포어이다 (이진값을 이용한 세마포어)
'프로그래밍응용 > Socket' 카테고리의 다른 글
| C기반 I/O Multithreading - 17. 멀티 쓰레딩 기반의 서버 (0) | 2021.02.05 |
|---|---|
| C기반 I/O Multithreading - 16. 뮤텍스와 세마포어(2) (0) | 2021.02.05 |
| C기반 I/O Multithreading - 14. 쓰레드의 치명적인 문제점 (0) | 2021.02.04 |
| C기반 I/O Multithreading - 13. 쓰레드의 생성과 소멸까지 (0) | 2021.02.03 |
| C기반 I/O Multithreading - 12. 멀티 프로세싱? 멀티 쓰레딩? (0) | 2021.02.03 |