C기반 I/O Multithreading - 15. 뮤텍스와 세마포어(1)
C기반 I/O Multithreading - 14. 쓰레드의 치명적인 문제점 C기반 I/O MultiThreading - 12. 멀티 프로세싱? 멀티 쓰레딩? 멀티 프로세싱에 이어서, 멀티 프로세싱의 단점이 보완되는 멀티 쓰레딩 개념이다. 사
typingdog.tistory.com
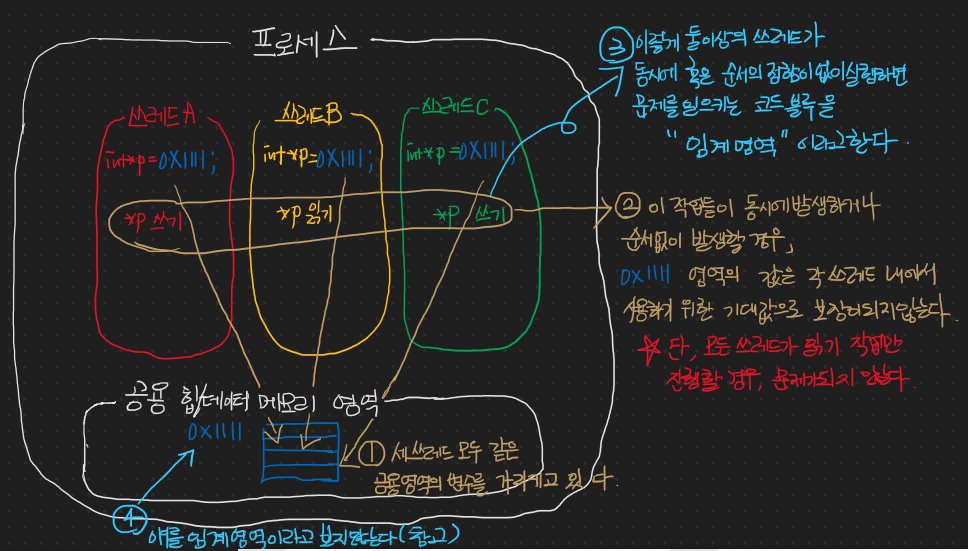
쓰레드를 동기화 하는 방법으로 뮤텍스에 이어서 세마포어다!
좀 더 구체적으로 정확히 이야기하자면 바이너리 세마포어이다.
바이너리 세마포어란
이 바이너리 세마포어는 0과 1을 사용하여 실행 순서를 컨트롤 한다. 다음은 바이너리 세마포어가 임계영역에 대한 접근 순서를 동기화하는 과정을 적어놨다.

쓰레드 A가 먼저 sem_wait() 함수를 호출하여 임계 영역에 접근한 상태에서 쓰레드 B가 sem_wait() 함수를 호출하여 블로킹에 걸렸다가, 쓰레드 A가 sem_post() 함수를 호출하여 쓰레드 B가 sem_wait() 함수 처리 가능 상태가 되어서 이를 호출하고, 쓰레드 B가 임계 영역에 접근한 뒤, sem_post() 함수를 호출하여 쓰레드 B가 임계 영역에서 빠져나오는 과정을 설명한 것이다.
좀 설명이 복잡했지만 다음과 같다.

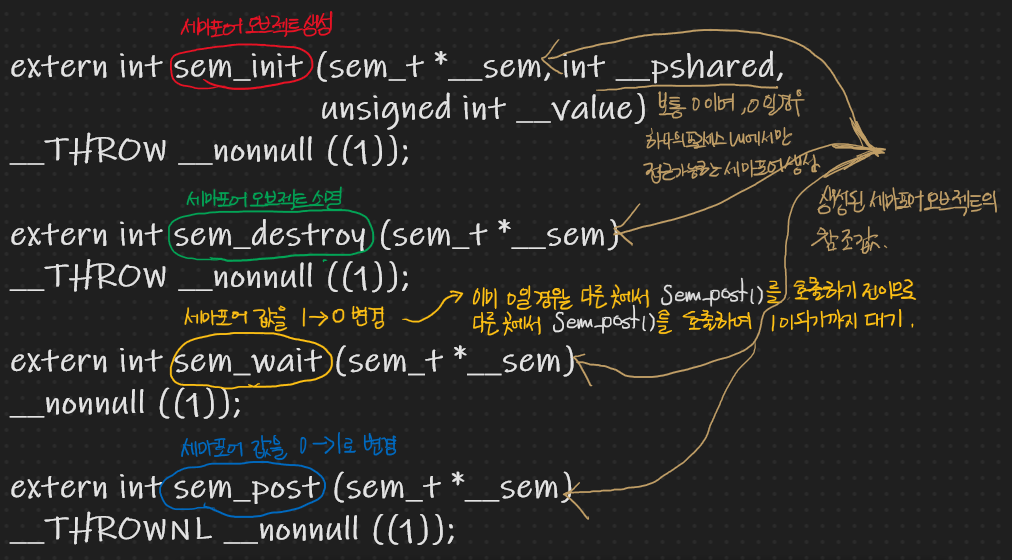
위에서 나온 함수들의 원형을 살펴보면 다음과 같다.
이어서 간단한 예제를 확인하겠다. 지난 예제의 보완이다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
|
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <pthread.h>
#include <semaphore.h>
sem_t semaphore;
int common_value = 0;
void* t_main_plus(void *arg);
void* t_main_minus(void *arg);
int main(void)
{
pthread_t tid1, tid2;
sem_init(&semaphore, 0, 1);
// 세 번째 인자를 0으로 넣으면 sem_wait을 먼저 호출한 쓰레드에서 블로킹이 발생하는 것을 확인할 수 있다.
pthread_create(&tid1, NULL, t_main_plus, NULL); // 쓰레드 생성
pthread_create(&tid2, NULL, t_main_minus, NULL); // 쓰레드 생성
pthread_detach(tid1); // tid1 에 해당하는 쓰레드가 종료됨과 동시에 소멸.
pthread_detach(tid2); // tid2 에 해당하는 쓰레드가 종료됨과 동시에 소멸.
sleep(7); // 종료되지 않도록 대기.
sem_destroy(&semaphore);
printf("메인함수가 종료됩니다. [common_value의 최종 값 : %d]\n",common_value);
return 0;
}
void* t_main_plus(void *arg)
{
int i = 0;
printf("t_main_plus 쓰레드가 연산을 시작합니다. \n");
sem_wait(&semaphore);
for(i=0; i<1000000; i++) // for을 중복해서 쓴 것은 100번 type을 검사하는 것보단 났다고 생각.
common_value+=1;
sem_post(&semaphore);
printf("t_main_plus 쓰레드가 종료됩니다.\n");
return NULL;
}
void* t_main_minus(void *arg)
{
int i = 0;
printf("t_main_minus 쓰레드가 연산을 시작합니다. \n");
sem_wait(&semaphore);
for(i=0; i<1000000; i++) // for을 중복해서 쓴 것은 100번 type을 검사하는 것보단 났다고 생각.
common_value-=1;
sem_post(&semaphore);
printf("t_main_minus 쓰레드가 종료됩니다.\n");
return NULL;
}
|
cs |

여러 차례 실행해도 common_value 값은 딱 0으로 맞아 떨어진다. 세마포어가 교착 상태도 없이 잘 수행해낸 것으로 확인되는 실행 결과이다.
이로서 쓰레드 동기화에 관련된 내용은 마무리이고 다음 포스팅에는 뮤텍스를 이용한 서버 프로그램 작성이다.
'프로그래밍응용 > Socket' 카테고리의 다른 글
| C기반 I/O Multithreading - 17. 멀티 쓰레딩 기반의 서버 (0) | 2021.02.05 |
|---|---|
| C기반 I/O Multithreading - 15. 뮤텍스와 세마포어(1) (0) | 2021.02.04 |
| C기반 I/O Multithreading - 14. 쓰레드의 치명적인 문제점 (0) | 2021.02.04 |
| C기반 I/O Multithreading - 13. 쓰레드의 생성과 소멸까지 (0) | 2021.02.03 |
| C기반 I/O Multithreading - 12. 멀티 프로세싱? 멀티 쓰레딩? (0) | 2021.02.03 |