C Data Structure - 그래프란?
드디어 그래프에 대한 포스팅이다. 여러가지 병행하며 정리할 것도 너무 많아서 ㅋㅋ 미루고 미루다 이제 올리게 된다. 오늘은 그래프의 기본 중에 기본인 용어 및 정의 정리이다. 그래프란? 먼
typingdog.tistory.com
C Data Structure - 그래프의 기본
드디어 그래프의 기본 코드이다. 이전 포스팅에서 설명했듯이, 그래프를 표현하는 방법 중 인접 리스트 방법을 이용하여 기본적인 그래프를 구현해 볼 것이다. 그 인접 리스트에 해당하는 방법
typingdog.tistory.com
일단, 위의 그래프 기본들을 기반으로 작성되기 때문에.. 링크해둔다.
뭐 BFS니 DFS니 이상한 용어 써가면서 아는 척 오졌던 학과 동기들 보면 이제 이렇게 생각하라.
대단한 친구들이네
근데 사실, 이상한 용어가 나와서 오히려 겁 먹고 어려울지 모르겠지만 조금만 이해하면 그렇게 어렵지 않다.
BFS 나 DFS 모두 Search의 일종이다. 뭐 말로만 Search지 순회다 순회. 순회하면서 원하는 값이 나오면 조건문으로 캐치하면 그게 Search이지 무엇이겠는가?
아무튼 두 개념 모두 순회인데, 순회하는 방법이 다르다. 그래서 두 가지를 모두 동시에 기록해 두려고 한다.
DFS (Depth First Search)
DFS는 Depth First Search 로 깊이 우선 탐색이다. 말 그대로 우선적으로 그래프를 깊게 깊게 파고 들어간다는 것이다. 그렇게 전부 파고 들어 갔다면 다시 되돌아 나오면서 깊게 파면서 놓쳤던 주변을 살펴보며 나오는 형식이다.

위 그림과 같은 식인데, 윤성우 교수님의 자료구조 책에서는 다음과 같이 표현한다. "너니까 이야기해주는거야" 하면서 깊고 친한 관계라고 생각하는 친구들에게만 비밀 이야기를 전달한다. 그러다보니 3번과 같은 정점에게도 퍼져있는 비밀 이야기가 소문이 나는 상황에 비유를 하셨다ㅋㅋ
중요한 것은 돌아 나오는 것과 각 정점들의 방문 여부이다. 이 둘을 어떻게 관리하고 코드로써 표현할 것인지가 큰 쟁점이다.
첫째로 돌아 나온 다는 것은 그 발자취를 기록하면 된다. 기록할 때 그냥 순서대로 기록하고 기록한 순서대로 다시 보는게 아니라 돌아나가는 것은 역재생하는 것과 같으므로 스택 자료구조를 이용한다.
둘째로 정점들의 방문 여부는 인덱스 값과 정점 값을 매칭 시킨 flag 역할을 1차원 배열로 처리를 하면 된다.
참고>>
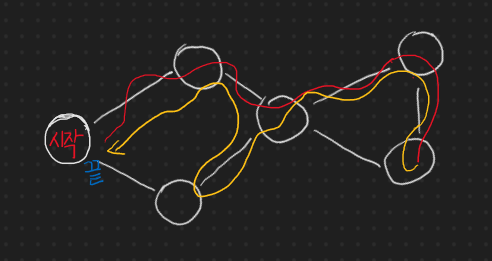
이런 경로 또한 가능하다. 구현해 보면 알겠지만 하나의 정점에 연결된 정점들 중 어떤 것을 선택하는지에 대한 로직은 순회 로직에 들어가지 않는다. 그러니까 시작 정점에서 왼쪽 정점으로 갈지, 오른쪽 정점으로 갈지를 중요시 하지 않는다는 소리이다. 이는 정점간 연결을 나타내는 자료구조 내에서 어떤 순서로 연결 정보를 저장했는지에 따라서 다르게 나온다. 그니까 어떤 경로든 해당 탐색의 기본 원리에만 들어 맞다면 경로 순서의 맞고 틀리고를 따지는건 의미가 없다는 소리이다.
BFS (Breadth First Search)
반면에 BFS는 Breadth First Search 로 너비 우선 탐색이다. 말 그대로 우선적으로 넓게 넓게 퍼뜨리며 그래프를 파고들겠다는 것이다. 그러니까 어떤 정점을 순회하기만 했다 하면 바로 그냥 그 해당 정점에 연결된 모든 정점에게 방문하는 것이다.

이건 약간 예로 들자면, 정책 발표에 따른 메시지 퍼짐이다! 출발 지점에서 정책을 발표한다. 그 양 옆 정점은 그 해당 정책을 티비를 통해 실시간으로 들은 정점들이고, 그리고 나서 그 실시간으로 들은 정점들이 지인을 만날 때마다 그 정책에 대해서 이야기하는 모습 같다고 비유할 수 있다.
중요한 것은 방문/순회 차례에 대한 기록과 각 정점들의 방문 여부이다. 이 둘을 어떻게 관리하고 코드로써 표현할 것인지가 큰 쟁점이다.
첫째로 물론 각 정점들의 방문 여부는 위에서와 마찬가지로 flag 역할의 1차원 배열로 충분하다.
둘째로 방문/순회 차례에 대한 기록은 위 DFS와는 조금 다르다. 방문한 정점과 연결된 정점들을 모두 방문하고, 그 다음 순서까지 정한 뒤 넘어가야헌다 그것이 BFS에서의 순회라고 보면 된다. 그러기 위해서는 꼭 순서를 기록해야한다. 그렇지 않으면 순회에 비효율이 생길 수 있다. 이 때 사용하는 것이 큐이다
이렇게 두 개념을 코드를 통해 구현해 볼 것이다
'프로그래밍응용 > C 자료구조' 카테고리의 다른 글
| C Data Structure - 너비 우선 탐색(Breadth First Search Graph) (0) | 2021.01.30 |
|---|---|
| C Data Structure - 깊이 우선 탐색(Depth First Search Graph) (0) | 2021.01.29 |
| C Data Structure - 그래프의 기본 (0) | 2021.01.28 |
| C Data Structure - 그래프란? (0) | 2021.01.28 |
| C Data Structure - 이진 탐색 트리 4 (마지막) (0) | 2021.01.24 |