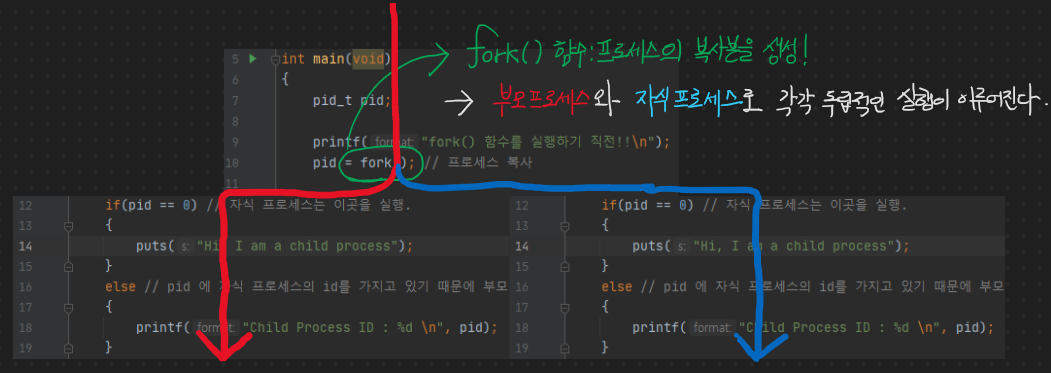
C기반 I/O MultiThreading - 12. 멀티 프로세싱? 멀티 쓰레딩?
멀티 프로세싱에 이어서, 멀티 프로세싱의 단점이 보완되는 멀티 쓰레딩 개념이다. 사실 단점이 보완되기는 하는데 함께 딸려오는 문제 거리도 만만치 않기 때문에 좀 상세히 볼 필요가 있다ㅋ
typingdog.tistory.com
C기반 I/O MultiThreading - 13. 쓰레드의 생성과 소멸까지
C기반 I/O MultiThreading - 12. 멀티 프로세싱? 멀티 쓰레딩? 멀티 프로세싱에 이어서, 멀티 프로세싱의 단점이 보완되는 멀티 쓰레딩 개념이다. 사실 단점이 보완되기는 하는데 함께 딸려오는 문제 거
typingdog.tistory.com
쓰레드 이전 설명들이다. ㅋㅋ
이렇게 프로세스의 자식 프로세스의 반환 회수, 프로세스끼리 통신의 까다로움, 많은 메모리 자원 소모, 부담스러운 컨텍스트 스위칭의 오버 헤드 문제들이 거의 해결이 되는 전지전능한 쓰레드일 것이라고 생각했다.
그러나 언제나 그렇듯, 하나가 되면 하나가 문제가 생기는게 이치이듯이 쓰레드 또한 치명적인 문제가 있었다.
통신을 손쉽게 하기 위해서 힙이나 데이터 등의 공유 메모리 영역을 두었다. 아주 잘한 것이다. 그런데 이 공유 메모리 영역에서 여러 다른 기능을 하는 쓰레드들이 동일한 변수 등에 접근하여 CRUD가 일어나는 경우 문제가 생기는 것이다! 왜냐하면 다음과 같은 상황인 것이다.
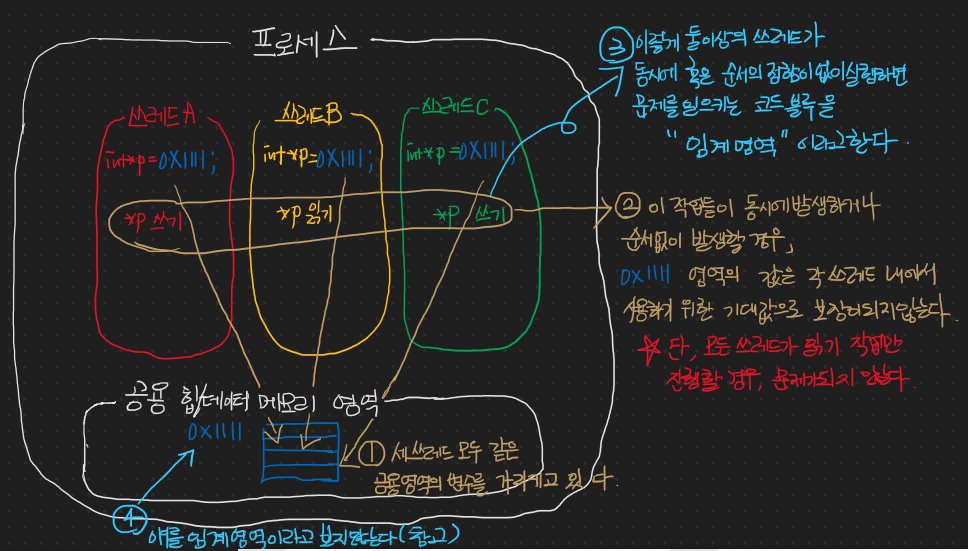
후 그리느라 너무 힘들었다. 위와 같은 상황을 이야기하는 것이다. 순서대로 읽으면 된다. 그림에서 나타내는 바를 설명하자면 같은 메모리 영역을 동시에 혹은 순서의 정함이 없이 읽고 쓰는 경우, 해당 메모리 영역의 값에 대한 기대값을 보장할 수 없게 된다. 왜 그럴까? 이 또한 그림으로 준비해보았다.

위의 순서대로 읽으면 된다.
결국, 쓰레드를 통한 병렬 처리가 진행될 때에는 프로세스와는 달리 공통적인 메모리 영역이 존재한다. 그래서 여기서 선언된 공통적인 변수에 동일한 임계 영역을 갖는 쓰레드들이 순서의 정함이 없거나, 동시에 접근을 하는 경우, 해당 변수로부터의 기대값을 보장할 수 없는 것이다. 다음 예를 통해서 확인해보겠다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
|
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <pthread.h>
int common_value = 0;
void* t_main_plus(void *arg);
void* t_main_minus(void *arg);
int main(void)
{
pthread_t tid1, tid2;
pthread_create(&tid1, NULL, t_main_plus, NULL); // 쓰레드 생성
pthread_create(&tid2, NULL, t_main_minus, NULL); // 쓰레드 생성
pthread_detach(tid1); // tid1 에 해당하는 쓰레드가 종료됨과 동시에 소멸.
pthread_detach(tid2); // tid2 에 해당하는 쓰레드가 종료됨과 동시에 소멸.
sleep(7); // 종료되지 않도록 대기.
printf("메인함수가 종료됩니다. [common_value의 최종 값 : %d]\n",common_value);
return 0;
}
void* t_main_plus(void *arg)
{
int i = 0;
printf("t_main_plus 쓰레드가 연산을 시작합니다. \n");
for(i=0; i<1000000; i++) // for을 중복해서 쓴 것은 100번 type을 검사하는 것보단 났다고 생각.
common_value+=1;
printf("t_main_plus 쓰레드가 종료됩니다.\n");
return NULL;
}
void* t_main_minus(void *arg)
{
int i = 0;
printf("t_main_minus 쓰레드가 연산을 시작합니다. \n");
for(i=0; i<1000000; i++) // for을 중복해서 쓴 것은 100번 type을 검사하는 것보단 났다고 생각.
common_value-=1;
printf("t_main_minus 쓰레드가 종료됩니다.\n");
return NULL;
}
|
cs |
서로 다른 연산을 하는 두 t_main_plus, t_main_minus 함수가 존재한다. 그리고 이 함수들은 전역 변수인 common_value 변수의 값을 +1, -1 조작하는 임계 영역을 가지고 있다.
그래서 각각 백만 번씩 1을 더하거나 빼도록 쓰레드를 동시에 실행하고 있는 상황이다.
t_main_plus에서는 백만번을 더하고, t_main_minus에서는 백만번을 빼니까 결국 둘이 상쇄되서 0이 되는 것이 정상 아닌가? 싶지만 결과를 확인해보자.



아니 값이 이렇게도 다를까 싶다. 임계 영역으로 인해 기대 값이 전혀 보장되고 있지 않는 상태이다.
이 정도 예제이면 확실히 임계영역, 즉 쓰레드의 문제가 어떤 것인지 확실하게 이해가 될 것이라고 생각한다. 다음 포스팅에서는 이를 해결하는 방법에 대해서 올릴 것이다.
근데 사실 이를 해결하려면 방법은 하나다. 동시에 접근을 막거나 연산의 순서를 직접 정하는 것 뿐이다. 이 기본적인 해결 방법을 토대로 여러 방법들이 등장할 것이다.
'프로그래밍응용 > Socket' 카테고리의 다른 글
| C기반 I/O Multithreading - 16. 뮤텍스와 세마포어(2) (0) | 2021.02.05 |
|---|---|
| C기반 I/O Multithreading - 15. 뮤텍스와 세마포어(1) (0) | 2021.02.04 |
| C기반 I/O Multithreading - 13. 쓰레드의 생성과 소멸까지 (0) | 2021.02.03 |
| C기반 I/O Multithreading - 12. 멀티 프로세싱? 멀티 쓰레딩? (0) | 2021.02.03 |
| C기반 I/O Multiprocessing - 11. 프로세스 정리 및 IPC (0) | 2021.02.03 |