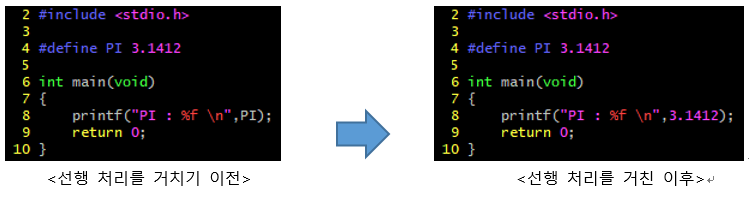
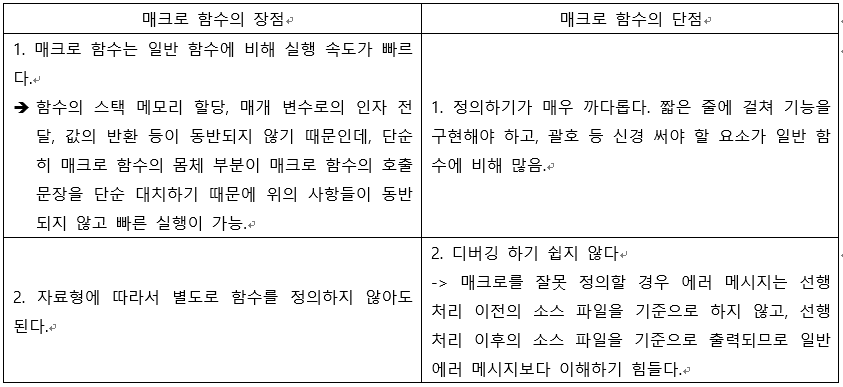
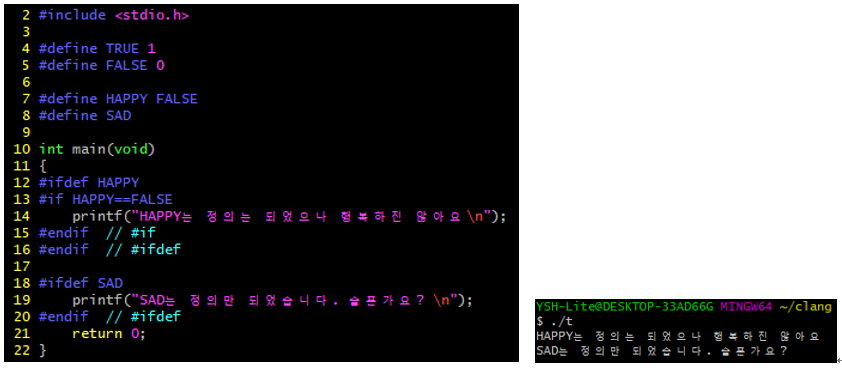
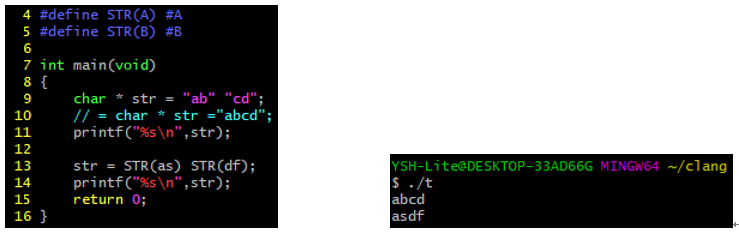
집에다가 Ubuntu Server 20.04를 설치했다.
git 서버 / svn 서버 / 서비스 서버 용도로 사용하려고 하는데 GUI 환경은 필요없기 때문이다. 설치하고 놀랐던 점은 바로 아래과 같다!!!
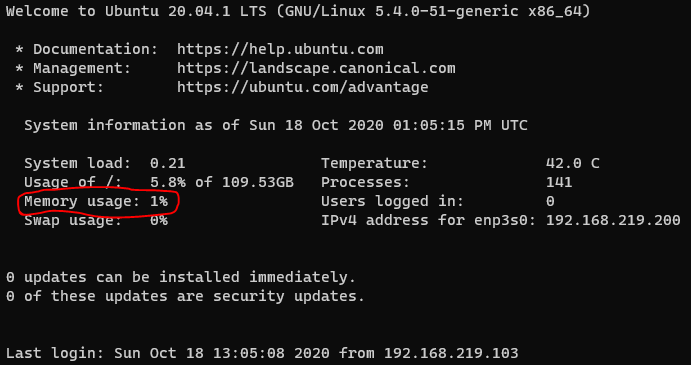
역시 서버라 그런지 메모리 사용량이 실화인가 싶을 정도이다. (gitlab 이나 svn 서버 올리면 내나 그 타령이겠지만ㅋ)
뭐 아무튼 용도가 서버 용도인만큼 내가 원할 때 상시 접속을 할 수 있어야 하는데, 전기요금으로 인해 서버를 항시 켜둘 수도 없기 때문에 선택한 것은 WOL이다!
Wake On Lan 기능으로 랜 신호를 이용하여 컴퓨터를 깨우는 방법이다!

위와 같이 웹으로 접속하여 공유기한테 WOL 신호를 컴퓨터에게 주라고 명령하는 것이다 ㅋㅋㅋ
그렇지만 깨움을 당하는 입장인 OS에서도 (마음의) 준비가 되어 있어야 하기 때문에 어느 정도 설정이 필요하다. 그 설정 때문에 이렇게 또 귀찮게 포스팅을 하게 되었다. 자주 쓰니까 기록할 겸!
1. 필요 명령 설치
sudo apt install net-tools ethtool wakeonlan
위 명령어를 통해 필요한 부분을 먼저 설치하자.
2. 이더넷 인터페이스 이름을 알아보자
내가 깨울 컴퓨터의 네트워크 랜 카드에 배정된 이더넷 인터페이스 이름을 알아야 한다. 이를 알기 위해서는 먼저,
ifconfig 명령을 실행하여

이더넷 인터페이스 이름을 알아낸다.
3. /etc/network/interfaces 설정
sudo vim /etc/network/interfaces
위의 명령을 통해 위에서 알아낸 인터페이스 이름을 기입하고 저장한다.
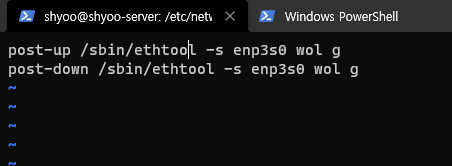
post-up /sbin/ethtool -s 이더넷 인터페이스 이름 wol g
post-down /sbin/ethtool -s 이더넷 인터페이스 이름 wol g
4. /etc/netplan 설정
고정 아이피만을 기준으로 적용한다. (wol 자체가 서버로 이용하려는 경우가 많기 때문에 다른 아이피들도 설정할 일이 많아서 그냥 고정 아이피로 설정해두는게 심신에 평안을 가져다 준다 ㅋㅋ)
/etc/netplan 디렉토리 내에 ~~.yaml 파일이 있는데 이를 다음 명령을 통해 열고 아래와 같이 수정한다.
sudo vim /etc/network/interfaces

빨간 박스 부분만 추가하면 된다.
그리고 나서 아래의 명령어로 적용을 해준다.
sudo netplan apply
우분투 18.04 부터 /etc/network/interfaces 를 수정하는 것은 적용이 되지 않는다는 정보가 있어서 netplan 부분 설정이 필요해서 넣었다.
5. 시작 스크립팅 작성 ( 4번까지 적용해도 작동이 안될 경우 강제로 wol 기능을 켜도록 작성 )
먼저, 스크립트를 작성할 디렉토리를 생성한다.
sudo mkdir /etc/wol
위 디렉토리 안에 다음과 같은 내용을 작성하고 저장하여 wakeonlan.sh 스크립트를 생성한다.
sudo vim /etc/wol/wakeonlan.sh # 스크립트 생성 및 쓰는 명령어
---- 아래는 안에 들어가야할 내용 ----
#!/bin/sh
/sbin/ethtool -s 인터페이스이름 wol g
---- 위에는 안에 들어가야할 내용 ----
실행 퍼미션 설정
sudo chmod u+x /etc/wol/wakeonlan.sh
서비스 정의 파일(wakeonlan.service)을 작성한다. ( 컴퓨터가 켜질 때마다 실행할 서비스로 등록하는 과정 )
vim /etc/systemd/system/wakeonlan.service
---- 아래는 안에 들어가야할 내용 ----
[Unit]
Description=Enable Wake-On-LAN
[Service] Type=simple
ExecStart=/etc/wol/wakeonlan.sh
Restart=always
[Install]
WantedBy=multi-user.target
---- 위에는 안에 들어가야할 내용 ----
아래의 명령어를 통해 서비스 등록 및 시작을 한다.
sudo systemctl enable wakeonlan.service
sudo systemctl start wakeonlan.service
아래처럼 재부팅 후 명령어를 쳤을 때(인터페이스 이름은 각자 맡게 ㅋ), g 값이 뜬다면 성공인 것이고, 다시 컴퓨터를 종료한 후 wol 신호를 보내보자!

'리눅스:Ubuntu > Desktop' 카테고리의 다른 글
| 우분투 20.04에서 JetBrains 프로그램 설치 및 런처에 아이콘 추가. (0) | 2020.10.13 |
|---|