객체 포인터가 참조를 할 때, 포인터 연산의 기준으로 두는 것은 실제 가리키는 객체의 자료형이 아니라, 선언된 포인터의 자료형을 기준으로 한다. 그로 인해 포인터 변수의 자료형에 따라서 호출되는 함수의 종류가 달라진다.
이와 같은 상황을 발생하지 않도록 가상함수 라는 문법을 제공.
위 소스에서 포인터 변수의 자료형을 기준으로 판단하여 호출되는 함수를 결정하는 상황을 발생시킬 수 있는 오버라이딩 된 함수들이다. 이러한 오버라이딩 된 함수들을 "가상 함수"로 만듦으로써, 실제 가리키는 객체의 자료형을 기준으로 판단하여 호출 함수를 결정하게 만들 수 있다.
가상함수로 만드는 것은 위의 소스처럼 해당 함수 앞에 "virtual" 키워드를 붙임으로써 완성한다.
함수를 가상함수로 만들게 되면 이를 "오버라이딩 하는" 함수들 또한 virtual 키워드를 붙이지 않더라도 자동으로 가상 함수화 된다.
순수 가상함수, 추상 클래스
클래스 중에는 객체 생성을 목적으로 하지 않는 클래스가 존재한다. 상속을 위한 Base 클래스로서 존재하는 클래스들이 존재하는데, 이를 객체로 생성하게 되는 것은 개발자의 실수이다.
이러한 실수를 방지하기 위해 가상함수를 순수 가상함수로 선언하여 객체의 생성을 방지한다.
순수 가상함수란? 함수의 몸체가 정의되지 않은 함수를 말한다. 이를 포함한 클래스는 불완전한 클래스이기 때문에 객체를 생성하게 되면 컴파일 에러가 발생한다. 이러한 순수 가상함수가 멤버 함수로 포함된 불완전한 클래스를 추상 클래스라고 한다.
가상 소멸자
소멸자 또한 가상함수 선언이 된다. Base 클래스를 Derived 클래스가 상속하였을 때, Derived 클래스의 생성자를 호출하고 바디를 실행하기 이전에 Base 클래스 생성자를 호출한다. 이 두 생성자는 멤버 변수의 동적 할당을 수행한다고 가정한다! 이 때, 객체 포인터를 이용하여 객체를 할당하였다면 소멸자 또한 객체 포인터의 자료형을 기준으로 판단하여 경우에 따라서는 Derived 클래스의 소멸자가 실행되지 않을 수 있다.
이를 방지하기 위해서 소멸자에 virtual 키워드를 붙임으로써 해결한다.
다형성(polymorphism)
문장은 같은데 결과는 다른 것을 다형성이라고 한다. ( 동질이상, 열혈 C++ 참고 ) 오버라이딩, 순수 가상함수 개념이 다형성에 해당한다. 이는 참조자(레퍼런스) 에서도 똑같이 적용된다.
멤버함수의 진실
멤버 변수는 객체 내에 존재한다. 그러나 사실, 멤버 함수는 객체 안에 존재하지 않는다. 멤버 함수는 사실, 메모리 한 공간에 위치하고, 해당 클래스로 선언되어 생성된 객체들이 이 한 공간에 위치한 멤버 함수들을 공유하는 형태로 존재한다.
V-Table
위와 같은 두 클래스는 V Table이라는 가상 함수 테이블을 구성하게 된다. 객체 생성이 되지 않더라도 컴파일러에 의해 가상함수 테이블을 만든다.
위의 예제에 해당하는 가상 함수 테이블은 2개가 다음과 같은 형태로 구성이 된다.
유심히 살펴봐야 할 부분은 Derived 클래스의 테이블인데, 이 테이블에서는 상속을 받은 입장인대도 불구하고, Base::f1의 정보가 존재하지 않는다. 이는 오버라이딩 된 가상 함수의 정보는 존재하지 않고, 유도 클래스의 오버라이딩 한 가상 함수만이 존재한다.
위의 소스에서는 Base 클래스가 Derived 클래스를, DeepDerived 클래스가 Derived 클래스를 상속하고 있는 2단 상속이 이루어지고 있다. 위의 상황에서 다음과 같은 소스 코드는 에러 없이 실행이 가능하다.
정리를 해보자면, C++ 에서는 Base 클래스 형 포인터 변수는 Base 클래스의 객체 또는 Base 클래스를 직접적(Base 를 직접 상속) 혹은 간접적(Base를 상속한 Derived 클래스를 상속)으로 상속하는 모든 객체를 가리킬 수 있다.
왼쪽 위의 예제는 오른쪽 그림의 소스 코드에서 주석과 같이 실행이 된다.
위 소스와 결과에서 주목해야 할 여러 가지가 있다.
1. 상속 관계에서 Base 클래스 그리고 Derived 클래스들에 완전히 동일한 함수 (이름, 반환타입, 매개변수) 를 정의할 수 있다. >> 이를 "Overriding" 이라고 하고, 오버라이딩 된 함수들 중 Base 혹은 이전 Derived 클래스의 함수들은 가장 마지막 Derived 클래스의 함수에 의해 가려진다.
2. 객체 포인터를 이용하여 멤버 함수 등을 호출할 때에는 실제 참조하고 있는 객체를 기준하는 것이 아니라, 객체 포인터의 자료형을 기준으로 한다. >> 5번, 9번 줄에서 보았을 때, 5번 줄에서는 Base * 자료형이지만 실제로는 DeepDerived 객체를 가리킨다. 그러나 9번 줄에서 오버라이딩 된 함수 print()를 호출하였을 때, Base 클래스에 있는 함수를 호출한다. 이것이 증거이다.
포인터의 포인터는 포인터 변수를 가리키는 또 다른 포인터 변수를 뜻한다.마찬가지로 포인터의 포인터의 포인터는 포인터 변수를 가리키는 또 다른 포인터 변수를 가리키는 또 다른 포인터 변수를 뜻한다.
포인터 변수는 종류와 상관 없이 주소 값을 저장하는 변수인데, 다만 더블 포인터와 일반 싱글 포인터의 차이점은 가리키는 대상이 또 다른 포인터 변수인지, 일반 변수인지의 차이이다.
위의 예는 일반 변수, 싱글 포인터, 더블 포인터의 사용 예와 세 변수 간의 관계를 값으로 나타낸 예이다.
먼저, 7번 라인에서 일반 정수형 변수를 선언, 그 주소 값을 8번 라인에서 포인터 변수에 저장한다. 그리고 다시 그 포인터 변수의 주소 값을 9번 라인의 더블 포인터를 선언하고 저장한다. 다음은 11번 라인 ~ 13번 라인의 출력에 대한 결과를 나타내었다.
위의 실행 결과에서 첫 번째 결과 라인에서의 일반 정수형 변수의 주소 값을 출력 하였고, 이 주소 값을 두 번째결과 라인에서 싱글 포인터 변수에 값으로 대입되어 싱글 포인터 변수 pNum이 일반 변수 number를 가리키고 있는 형태를 이루었다. 그리고 마찬가지로 두 번째 결과 라인에서 싱글 포인터 변수의 주소 값을 출력 하였고, 이 주소 값을 세 번째 결과 라인에서 더블 포인터 변수에 값으로 대입되어 더블 포인터 변수 dpNum이 싱글 포인터 변수 pNum을 가리키는 형태를 이루고 있다.
두 번째 실행 결과 라인에서 * (애스터리스크) 연산자를 이용하여 pNum이 값으로 가지고 있는 주소에 접근하여 값을 출력한다.(가리키는 변수의 값을 출력) 세 번째 실행 결과 라인에서 **(더블 애스터리스크)를 이용하여 더블 포인터가 가지고 있는 싱글 포인터 주소에 접근하고 또 그 싱글 포인터가 가지고 있는 주소에 접근하여 값을 출력한다.(가리키고 가리키는 변수의 값을 출력)
사실, 참조의 더블 포인터(**)는 *(*더블 포인터 변수) 에서 소괄호가 생략된 형태이다.
포인터 배열의 포인터 형
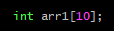
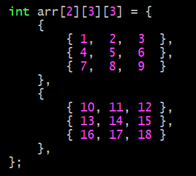
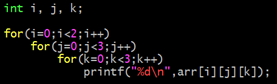
8번 라인에서 정수형 포인터 타입 배열을 선언하여 n1과 n2의 주소 값을 배열의 각 요소에 대입하였다. 1차원 배열 이름의 포인터 형을 배열 이름이 가리키는 요소의 자료형을 고려하여 결정하듯이 1차원 포인터 배열 이름의 포인터 형 또한 배열 이름이 가리키는 요소의 자료형을 고려하면 된다. 11번 라인에서 배열 이름과 배열의 첫 번째 요소의 주소 값을 출력했는데 그 결과는 배열 이름 arr과 arr 배열의 첫 번째 요소의 주소가 일치했다. 이 때 배열 이름은 int * 형의 요소를 가리킨다. 즉 1차원 포인터 배열의 배열 이름은 더블 포인터 상수라고 할 수 있겠다. 그렇기 때문에 9번 라인에서 더블 포인터 변수에 배열 이름 arr을 아무런 처리 없이 대입하더라도 문제 없이 대입이 된다. 이어서 12번 라인에서 더블 포인터 변수를 이용하여 더블 포인터 연산을 통하여 포인터 배열의 각 요소에 접근하여 값을 출력하는 예제이다.
리스트는 벡터와 디큐와 마찬가지로 순차 선형 콘테이너이다. 그래서 외부에서 볼 때에는 벡터와 완전히 동일한 듯 보이지만, 구조 자체부터 크게 다르다.
벡터는 순차 배열 형태였다면, 리스트는 이중 연결 리스트로 구현된다. 다음 그림과 같이 말이다.
위와 같은 이중 연결 리스트로 구현되어 있기 때문에 벡터에서의 순회 방법에서 아주 조금의 차이가 있다. begin() 부터 end() 까지 주소 값 비교를 통한 순회가 의미가 없기 때문이다. 무조건 노드의 링크를 타고 가는 방식의 포인터 연산으로 접근해야한다. ( 이는 연산자들이 오버로딩되어 자동으로 포인터 연산 되도록 구현되어 있음.)
또한 링크드 리스트로 구현되어 있기 때문에 인덱스가 없다. 그렇단 소리는 임의 접근이 불가능하다는 소리이고, 탐색을 할 때는 모든 노드를 링크를 타고 순회해야한다.
다만, 삽입이나 삭제를 할 때, 벡터에서는 요소들의 인덱스 재 조정 그리고 추가 메모리 공간 확장 및 복사/확장이 필요하지만 리스트에서는 링크를 변경하면 되므로 삽입/삭제 시에는 속도가 빠르다는 장점이 있다.
결국, 중간에서의 삽입 및 삭제가 빈번한 경우 사용하면 적합할 것 같다.
s
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
#include<iostream>
#include<list>
usingnamespacestd;
void print_list(list<int>& l)
{
list<int>::iterator list_it;
for (list_it = l.begin(); list_it != l.end(); list_it++) // 링크드리스트이기 때문에 <, > 연산이 의미가 없다.
cout<<"list iterator value : "<<*list_it <<endl;
return;
}
bool cond(int n) // 기본 조건에 의한 삭제를 위한 함수.
{
return n >901;
}
bool desc(int a, int b) // sort의 내림차순을 위함.
{
return a > b;
}
int main(void)
{
list<int> my_list;
list<int> new_list;
cout<<"push_front, push_back 함수 호출 --- --- ---"<<endl;
my_list.push_back(100);
my_list.push_back(200);
my_list.push_front(900);
print_list(my_list); // 900 100 200
cout<<"insert 함수 호출 --- --- ---"<<endl;
my_list.insert(--(my_list.end()), 999);
print_list(my_list); // 900 100 999 200
cout<<"remove & remove_if 함수 호출 --- --- ---"<<endl;
my_list.remove_if(cond); // 901 제거
my_list.remove(100); // 100 제거
print_list(my_list); // 900 200
cout<<"reverse 함수 호출 --- --- ---"<<endl; // 원소들을 뒤집어서 나열
my_list.reverse();
print_list(my_list); // 200 900
cout<<"sort 함수 호출 오름차순 --- --- ---"<<endl;
my_list.sort();
print_list(my_list); // 200 900
cout<<"sort 함수 호출 내림차순 --- --- ---"<<endl; // 식을 함수 형태로 주어 내림차순 구현
my_list.sort(desc);
print_list(my_list); // 200 900
cout<<"unique 함수 호출 --- --- --- "<<endl; // 인접한 데이터 중에 중복되는 요소들을 제거한다.(연속적으로 나오는 중복을 허용 X)
new_list.insert(new_list.begin(), 55);
new_list.insert(new_list.begin(), 33);
new_list.insert(new_list.begin(), 55);
new_list.insert(new_list.begin(), 55);
new_list.unique();
print_list(new_list); // 실행결과 : 55 33 55
cout<<"merge 함수 호출 --- --- --- "<<endl;
new_list.sort();
my_list.sort(); // 각각의 리스트들은 꼭 정렬되어 있어야 한다.
new_list.merge(my_list); // 복사(copy)하는 것이 아니라 요소의 이동(move)이다.
print_list(new_list); // 실행결과 : 33 55 55 200 900
print_list(my_list); // 실행결과 : 비어 있음 -> 이동했기 때문에
cout<<"splice 함수 호출 --- --- --- "<<endl;
my_list.push_front(300);
my_list.push_front(100);
my_list.splice(my_list.begin(), new_list); // 복사(copy)하는 것이 아니라 요소의 이동(move)이다.
34번 라인처럼 insert시, 임의 접근이 불가능하므로 포인터 연산(오버로딩된)을 통해 위치를 명시한다. 그리고 remove_if 함수를 통해 조건부 삭제가 가능한데, 이 때 조건은 13번 라인의 bool 반환 타입의 함수 형태로 기입한다. 함수의 이름을 적으면 된다.
50번 라인에서 sort 함수를 통해 기본적인 오름차순 정렬이 가능한데, 내림차순이나 다른 형태의 정렬을 위해선 remove_if 처럼 조건을 전달해야한다. 17번 라인의 함수 이름을 전달하면 된다.
59번 라인의 unique 함수는 인접한 데이터 중에 중복 요소가 있으면 중복을 제거한다. 내가 가만히 보니, 11/11/22/22 는 11/22 로 중복을 제거하지만 11/22/11/22인 경우는 중복이 제거가 되지 않는다... 참으로 이상하다
62번 라인과 70번 라인의 merge와 splice는 병합의 기능을 하는데, 참으로 불편한게 이 두 함수를 사용하기 위해서는 병합할 두 요소들이 모두 일정한 방법으로 정렬이 되어 있어야 한다는 점이다. 참으로 딱하구나... 또한 병합할 때에는 요소들 간의 복사가 이루어지는게 아니라 잘라내기&붙혀넣기 즉, 요소의 이동이 이루어지기 때문에 병합하는 쪽은 merge() 및 splice() 함수 호출 후에는 텅 비어있다.. 그런데 이것은 뭐 당연하다고 생각된다. 링크를 바꾸는 것이기 때문에!
상속이란? (열혈 C++, 윤성우) "기존에 정의해 놓은 클래스를 재활용을 하기 위한 목적으로 만들어진 문법"이라고 한다.
그러나, 이는 과거에 상속을 바라봤던 관점이라고 한다. 그렇다면 상속을 어떤 관점으로 봐야 하고, 왜 필요한지 이해할 필요가 있다고 생각한다.
상속이 필요한 이유
객체지향 언어에서는 데이터적인 성격이 강한 데이터 클래스와 그 데이터 클래스를 이용하여 어떤 여러 기능들의 처리를 담당하는 컨트롤 클래스(혹은 핸들러 클래스)가 필요하다.
하나의 주제 및 테마에 대한 데이터 클래스 + 해당 데이터 클래스에 맞는 컨트롤 클래스
그런데 상속이라는 어떤 개념을 사용하지 않은 상태에서 비슷한 주제에 대한 다른 데이터 클래스를 추가하게 된다면 그 데이터 클래스에 대한 기능을 수행할 수 있도록 기존 컨트롤 클래스 모두를 갱신해야 한다. 이는 대공사가 아닐 수가 없다.
-> 시시각각 변하는 여러 요구로 인한 변경에 대응하는 프로그램의 유연성과 기능을 추가함으로써 프로그램이 확장되는 확장성이 부족하다고 표현한다.
"탈 것"을 주제로 예를 들어 보았을 때,
1) 상속을 사용하지 않을 경우
기차 클래스/ 기차 기능을 수행하는 컨트롤 클래스
이렇게 구성하고 기차를 운영하는 프로그램을 작성했는데, 어느 날 비행기를 추가한다고 한다. 이런 경우에는
기차 클래스 / 비행기 클래스
기차 기능 수행 컨트롤 클래스 / 비행기 기능 수행 컨트롤 클래스
혹은
기차 클래스 / 비행기 클래스
기차 기능, 비행기 기능 수행 컨트롤 클래스
이렇게 대대적인 공사가 필요하다.
2) 상속을 사용하는 경우
비행기, 기차 등의 최소한의 공통점을 이용한 부모 클래스 / 컨트롤 클래스 ▽ (상속) ▽ 비행기, 기차, 자동차 등..
기차 클래스 외에 다른 클래스가 추가되는 경우에는 추가한 후 상속하고, 간단한 수정만 하게 되면 컨트롤 클래스까지 추가 수정하는 대대적인 공사를 막을 수 있다.
상속
간단하게 자식이 부모로부터 재산을 물려받는 행위를 상속이라고 하는데 객체지향 프로그래밍 언어에서는 재산 뿐만 아니라 행동 및 성격, 사상 등의 모든 것이 상속의 대상이 된다!
부모 ------ (상속) ------> 자식 키, 재산, 집 문서(데이터적인 성격) 하는 일, 습관적인 행동(기능적인 성격)
위 소스에서는 child 클래스가 parent 클래스를 상속받고 부모가 물려준 money 값을 출력하는 예제 소스이다. child 클래스 내에서 50번 줄의 함수 호출은 parent 클래스의 함수를 호출하고 있다. 이는 child 가 parent 를 상속받았기 때문에 가능한 호출이다. 상속은 34번 줄과 같이 " : 접근제한 상속_대상_클래스 " 형식으로 이루어진다.
그리고 57번 줄과 같이 child 클래스만 이용하여 선언했지만 parents 클래스를 상속받기 때문에 parents 클래스에 해당하는 생성자 호출 및 초기화 또한 child 클래스가 담당해야 한다. 관련 부분이 40번 줄, 이니셜라이저를 통하여 부모 클래스의 생성자가 호출되고 있음을 알 수 있다. 이니셜라이저를 통한 초기화이기 때문에 parent 클래스의 생성자는 child 생성자 보다도 앞서 본체까지 모두 실행되고 그 뒤에 child 생성자의 본체가 실행된다.
-> 이는 정말 당연하게도 부모가 존재해야 자식에게 상속을 할 수 있는 것처럼 부모가 먼저 객체화 되어야 자식 또한 상속받은 상태로 객체화 할 수 있기 때문이다.
상속 시 부모 클래스의 private 영역 접근
위의 예제에서 child 클래스가 parent 클래스를 상속받은 경우, child 클래스 내에서 parent 클래스의(부모 클래스) private 영역을 직접 접근이 가능한가가 문제이다.
위의 경우는 불가능하다. 아무리 상속을 받았다고 하더라도 부모 클래스의 private 영역은 자식 클래스에서도 직접 접근이 불가능하다. 이렇게 상속 관계에서 또한 정보 은닉 개념이 지켜진다.
private 영역은 부모의 사생활 영역이라고 생각하면 된다. 부모의 뇌라고 생각하고, 자식이 부모의 뇌까지 상속받아서 무슨 생각을 하는지 알 수 있는 것은 아니지 않은가!
상속 설정된 객체를 생성 시, 생성자 / 소멸자 호출 순서
생성자 호출 순서 : 부모 클래스 생성자 body 호출 -> 자식 클래스 생성자 body 호출 소멸자 호출 순서 : 자식 클래스 소멸자 호출 -> 부모 클래스 소멸자 호출
이러한 호출 순서는 당연한 것이다. 왜냐하면 객체 생성 시 부모 클래스 객체가 먼저 생성이 되어야 다음으로 생성되는 자식 객체에게 상속될 수 있기 때문이다.
소멸자의 호출은 생성자의 호출 순서에 반대이다!
지역변수의 호출 순서와는 무관하다. 지역 변수는 기본적으로 스택 구조에 담기기 때문에 LIFO 순서로 메모리 공간에서 해체되므로 이에 맞는 생성자/소멸자 호출이 이뤄진다.
protected 접근 제어 지시자
접근 제어 지시자 정리
private: 외부에서 이 영역에는 접근 불가하며, 상속 관계에서의 derived 클래스에서도 또한 접근이 불가능하다. 오직 해당 클래스의 멤버 함수를 통한 접근(내부 접근)만 허용 protected : 외부에서 이 영역에는 접근 불가하나 private와 다른 점은 상속 관계에서 derived 클래스에서 이 영역에 직접 접근이 가능하다. public: 외부, 내부, 상속 관계에서의 모든 접근을 허용함.
세 가지 상속 형태
상속하는 방법에는 3가지 형태가 존재한다. public, private, protected 상속이 존재한다. 하지만 이러한 세 가지 상속들은 Base 클래스의 접근 제어 지시자와 함께 관련이 있기 때문에 함께 보아야한다.
Base 클래스의 접근 제어 지시자 + 세 가지 중 하나에 해당하는 상속 형태
이것이 결정하는 것은 바로!! 상속을 완료하였을 때, Base 클래스가 Derived 클래스에서 어떤 접근 권한으로 갱신되는지를 결정한다.
위의 표는 일반적으로 설명에 쓰이는 표. 이 포스팅에서는 조금 다른 방법으로 정리해보았다.
1.먼저 상속의 형태 쪽을 훌라후프와 같은 원이라고 생각하자! 범위가 넓을 수록 큰 원이 된다.
public 상속은 제일 큰 원/ protected 상속은 중간 크기 원 / private 상속은 가장 작은 원
2.그리고 Base 클래스 또한 원이라고 생각하는데 이 원을 1번에서 생각한 원에 떨어트려본다.
3.크기가 같은 경우는 쏙 빠져 나온다고 생각하자,
EX)
-public 상속의 원에 public 멤버를 넣게 되면 public 접근 제어 권한으로 갱신되어 상속!
-private 상속의 원에 public 멤버를 넣게 되면 private 원 크기만큼만 잘려서 나오므로 private 접근 제어 권한으로 갱신되어 상속!
-Base 클래스에서 private 멤버인 경우는 부모의 사생활이기 때문에 무슨 짓을 해도 외부 접근 / 상속 관계의 derived 클래스에서의 접근 모두 허용하지 않고 내부 접근만 허용하므로 접근 불가.
이 두 상속 관계의 클래스가 상속이 완료된 모습을 보게 된다면 (정확한 형태는 본인도 잘 모르겠으나 핵심만 확인하기)
이러한 식으로 권한이 재 결정된다. 이는 외부 혹은 Derived 클래스를 다시 상속받으려고 하는 클래스의 입장에서 바라보았을 때의 권한이 된다. Base 클래스 만을 바라보면 Base 클래스 권한 그대로 유지하고 봐야 한다.
상속을 고민할 때, 따져 봐야 할 조건
IS-A 조건 과 HAS-A 조건
IS-A 조건 : a는 b의 일종이다 라는 말이 성립할 경우, b를 Base 클래스로, a를 Derived 클래스로 정의.
HAS-A 조건 : a가 b 를 소유한다 라는 말이 성립할 경우, b를 Base 클래스로, a를 Derived 클래스로 정의 -> 그러나 HAS-A 조건은 상속이 아닌 소유의 관계로 풀면 된다. a의 멤버로 b를 선언하여 표현.
위와 같이 객체에 const 키워드를 선언하게 되면 이 객체를 대상으로는 const 멤버 함수만을 호출할 수 있다. 왜냐하면 const 키워드는 기본적으로 데이터 변경을 허용하지 않음을 의미하기 때문이다.
함수 오버로딩의 조건 : const
함수 오버로딩이 성립하기 위해서는 함수의 이름과 매개 변수 정보(자료형, 수) 등이 필요했는데 거기에 더해서 const 여부 또한 오버로딩의 조건이 될 수 있다.
클래스와 friend 선언
aBoy, bGirl이라는 두 클래스가 있을 때, aBoy 클래스가 bGirl 클래스를 friend 선언하게 되면 bGirl 클래스는 aBoy 클래스의 private 영역까지 직접 접근이 가능하다. 그러나 aBoy 클래스는 bGirl 클래스의 private 영역에 접근이 불가능하다 왜냐하면 aBoy 클래스 측에서만 bGirl 클래스를 friend로 인정했지만 bGirl 클래스는 aBoy 클래스를 friend로 인정하지 않았기 때문이다.
다음은 위의 상황을 나타내는 예제 코드이다.
전역 함수와 클래스 멤버 함수를 대상으로도 friend 선언이 가능하다. 함수를 friend 선언하게 되면 friend 선언된 함수들은 해당 클래스의 private 영역에 접근이 가능하다.
위의 예에서 특이한 점은 8번 라인처럼 B가 클래스 이름임을 선언해야 먼저 나오는 클래스 A에서 B가 무엇인지 식별을 할 수 있다. 그리고 friend로 선언된 함수들은 선언과 정의를 분리해줘야 하는 것 같다. (확인필요)
static 키워드
C언어 에서의 static 키워드
c언어에서의 static 키워드는 다음과 같은 의미를 지님.
1.전역 변수 필드에 선언되었을 때 -> 선언된 파일 내에서만 참조를 허용
2.함수 내에 선언되었을 때 -> 메모리의 데이터 영역에딱 한 번 생성과 동시에 초기화 되어 저장되며, 함수 내에서 그대로 지역적인 성격을 가지고 있지만, 함수가 종료되어도 소멸되지 않는다.
C++ 에서의 static 키워드
static 멤버 변수 ( = 클래스 변수 )
c++ 에서도 지니는 성질은 같다. static 멤버 변수로 활용을 하는데, 클래스 변수라고 한다.
위와 같이 5번 줄에서 클래스 내부에서 static 선언을 이용하여 생성한 변수를 클래스 변수 및 static 멤버 변수라고 하는데, 이는 일반 클래스의 멤버 변수와 같이 객체가 생성될 때마다 생성되는 것이 아니다.
해당 클래스의 객체가 생성되든지 안되든지 생성 여부와 상관없이 프로그램이 시작되면 메모리 공간에 독립적으로 딱 하나만 할당되어서 공유되는 변수이다! (생성과 소멸의 시기가 전역 변수와 동일!)
객체가 생성되지 않았을 때에도 메모리 공간에 할당되어 있다는 이야기는 static 멤버는 객체에 종속되어 있는 변수가 아니라 외부에 존재하는 변수라는 이야기다.
단, 클래스 내부에 선언하여 멤버처럼 사용할 수 있는 이유는 객체에게 멤버 변수처럼 접근할 수 있는 권한만 부여되었기 때문임.
private: / public : 영역으로 나뉘는 것은 static 멤버를 해당 객체 내애서만 쓸 것인지, 외부에서도 클래스 이름 및 객체 이름을 통해 접근 가능하게 할 것인지를 나타낸다.
10번 라인처럼 초기화 방법이 따로 존재하는데, C++에서는 자바처럼 클래스 내에서 초기화 하는 방식을 지원하지 않기 때문에 생성자 및 멤버함수를 통해서 초기화 시키는 방법이 있다. 그러나 이 생성자를 이용하여 초기화하는 방법을 사용할 경우, 객체가 생성되어 생성자가 실행될 때마다 static 멤버 변수가 초기화 되기 때문에 이 방법을 사용해서는 안 된다. 10번 라인과 같이 초기화를 시켜준다.
static 멤버 함수
static 멤버 함수 또한 static 멤버 변수와 같이 특성이 그대로 적용된다. 다만, 객체의 멤버로 존재하지 않기 때문에 다음과 같은 코드는 에러가 발생한다.
9번 줄에서 에러가 발생하는 이유는 static 멤버 함수는 실제로 객체의 멤버가 아니다. 소속 객체가 없기 때문에 9번 줄에서 지정된 number 는 어느 객체의 number 인지 알 수 있는 길이 없다. 그렇기 때문에 에러가 난다
-> 결국 static 멤버 함수 내에서는 static 멤버 변수, static 멤버 함수만 호출 가능하다.
c언어에서처럼 전역 변수를 이용한 카운팅 등을 static 멤버들을 활용하여 대체할 수 있다.
const static 멤버
const static 멤버는 static 멤버의 특성을 유지한 채 const 화 되어 값을 항상 일정하게 유지하기 때문에 다음과 같은 코드가 허용이 된다.
mutable 키워드
mutable 키워드를 사용하여 멤버 변수에 선언하게 되면 const화된 함수 내에서 멤버에 대한 값의 변경을 예외적으로 허용하겠다 라는 의미를 지닌다!