복사 생성자
l 초기화 스타일
다음은 초기화를 나타내는 예제이다.

위와 같이 11번 라인처럼 항상 대입 연산자를 통하여 초기화 해왔으나, 12번 라인과 같이 새로운 C++ 스타일로 초기화가 가능하다. 그리고 두 결과는 값이 대입되었다는 점에서 같다. 이는 복사 생성자와 관련 있는 개념이다.
- 객체의 초기화 방법

객체 초기화 방법 또한 여러 방법이 존재하는데 먼저 38번 라인은 26번 라인에서 정의해 둔 생성자를 통해서 상수를 받아 초기화를 진행한다. 그리고 39번 라인에서는 대입 연산자를 통하여 초기화를 진행한다. C언어에서는 구조체끼리 대입 연산 시킬 경우 멤버 대 멤버의 복사가 일어났다. 마찬가지로 39번 라인 역시 클래스 멤버들에 대해서 멤버 대 멤버 복사가 일어난다. 40번 라인 또한 C++언어 스타일의 초기화 방법으로 결과는 39번 라인과 똑같다. 39번 라인은 결국 40번 라인 형태로 변환이 일어난 후 초기화가 진행된다.
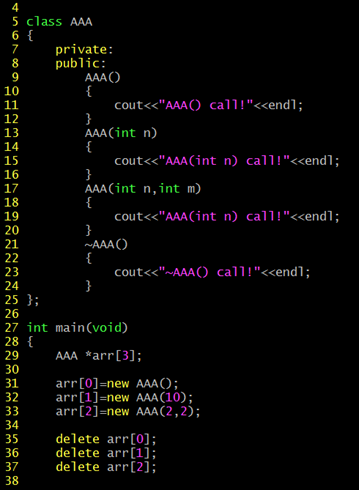
그런데 중요한 것은 객체가 생성될 때에는 무조건 생성자가 호출되어야 하는데, 38번 라인의 객체 생성에서는 26번 라인의 생성자가 호출되었다. 그러나 39번, 40번 라인의 경우 호출될 수 있는 생성자가 존재하지 않는다. (이미 생성자가 정의되었기 때문에 디폴트 생성자로는 현 상황을 설명할 수 없음)
이러한 경우는 디폴트 복사 생성자가 존재하기 때문에 에러 없이 실행이 가능한 것이다.
디폴트 복사 생성자를 예측해보자면 다음과 같은 형태로 구성되어 있다 복사 생성자를 따로 정의하지 않는다면 멤버 대 멤버의 복사를 진행하는 디폴트 복사 생성자가 자동으로 삽입된다.

다음은 정말 위와 같은 형태로 복사 생성자를 정의한 예제이다.


17번 라인에서 매개 변수를 참조자로 받는 복사 생성자를 직접 정의한 것을 확인할 수 있다. 이러한 복사 생성자는 33번이나 34번 라인과 같이 객체 간의 복사가 이루어질 때 호출되는 것을 확인할 수 있다.
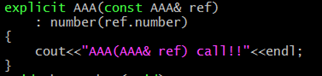
- explicit

39번 라인의 초기화 형태는 38번 라인 형태의 초기화 형태로 변환이 일어난 후에 복사 생성자를 호출하는데 이러한 변환은 묵시적인 변환이기 때문에 결과를 예측하기 힘들 수 있다. 그렇기 때문에 이러한 묵시적인 변환에 의한 호출을 허용하지 않기 위해서는 다음과 같이 explicit 키워드를 복사 생성자에 붙임으로써 묵시적인 변환을 일으키는 초기화 스타일에 대해 에러 메시지를 내어준다.
- 얕은 복사와 디폴트 복사 생성자의 문제점
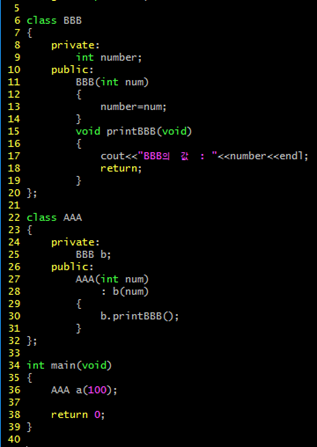
디폴트 복사 생성자는 멤버 대 멤버의 복사를 진행하는데 이러한 방법의 복사 형태를 ‘얕은 복사’ 라고 한다. 일반 변수 형태의 멤버 변수의 경우 문제가 없으나, 멤버 변수로 힙 메모리 영역을 가리키고 있는 포인터를 지니고 있다면 그 때에는 문제가 된다. 다음은 그 문제의 경우를 나타내는 예이다.

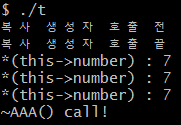
분명히 객체를 세 개 생성하였으니 소멸자는 세 번 호출되어야 한다. 그러나 위의 예에서는 소멸자가 딱 한 번 호출되었음을 확인할 수 있다. 소멸자를 호출하면서 delete 연산에서 에러가 나서 프로그램이 종료된 것이다. 그렇다면 delete 연산에서 오류가 난 이유는? 디폴트 복사 생성자의 얕은 복사 때문이다
a1 객체의 생성자가 호출 -> a1 객체 내의 number 할당 -> a2 객체의 디폴트 복사 생성자 호출 -> a1 객체 내의 number 가 가지고 있는 주소 값을 a2 객체 내의 number에 대입 -> a3 객체의 디폴트 복사 생성자 호출 -> a2 객체 내의 number 가 가지고 있는 주소 값을 a3 객체 내의 number에 대입
여기 까지는 생성자 호출 과정이다. 여기서 문제는 세 개의 객체들의 생성자가 모두 호출되면 a1, a2, a3 객체 내의 number는 모두 같은 메모리 위치를 가리키고 있다는 것이다. 그렇기 때문에 첫 소멸자에 해체한 이미 메모리를, 두 번째 소멸자의 실행에서 한번 더 해체하려는 과정에서 오류가 나는 것이다.
이렇게 멤버로 동적 할당이 필요한 객체 간의 복사 생성자는 멤버 대 멤버의 복사의 얕은 복사 형태로 이루어져서는 절대 안 된다. -> 깊은 복사를 위한 복사 생성자를 꼭 정의해야 한다.
다음은 깊은 복사를 행하는 복사 생성자를 정의한 예이다.


18번 라인에서 깊은 복사를 수행하는 복사 생성자를 정의한 결과 소멸자가 모두 정상 출력되는 것을 확인할 수 있다.
- 복사 생성자가 호출되는 시점
복사 생성자가 호출되려면 먼저 공통적으로 꼭 포함해야 할 기본 전제에 대해서 알고 있어야 한다.
1. 객체를 새로 생성해야 함
2. 그리고 생성과 동시에 동일한 자료형의 객체로 초기화 해야 함.(할당과 동시에 초기화)
복사 생성자의 호출되는 시점은 다음과 같이 세 가지 경우에 호출되는 시점이 될 수 있다. 이 세 가지 경우 모두 겉보기에는 다른 형태이지만 결국에는 객체를 새로 생성하고, 생성과 동시에 동일 자료형의 객체로 초기화 되는 경우인 것이다.
1. 기존에 생성된 객체를 이용해서 새로운 객체를 초기화 하는 경우
-> int num1=num2; 와 같은 상황으로 할당과 동시에 초기화가 일어 남.
-> AAA a1=a2; 의 경우 a1의 복사 생성자가 호출되어 a2의 값이 a1으로 복사됨.
2. Call-by-Value 방식의 함수 호출 과정에서 객체를 인자로 전달하는 경우
-> 함수가 호출되는 순간에 매개 변수가 할당됨과 동시에 전달된 인자의 값으로 초기화된다.
-> void func(AAA arg);에서 func(a1);으로 호출할 경우 arg의 복사 생성자가 호출되어 a1의 값이 arg로 복사됨.
3. 객체를 반환하되, 참조형으로 반환하지 않는 경우
-> 함수가 값을 반환하면, 별도의 메모리 공간이 할당되고, 이 공간에 반환 값이 저장(초기화)된다. 이런 식으로 변수 혹은 객체로서 별도 메모리에 저장되어 임시 변수 혹은 객체로 남아 있어야 함수 등을 이용하여 출력을 하거나, 변수에 대입을 할 수 있기 때문이다. 이렇게 객체가 반환될 때, 임시 객체의 복사 생성자가 호출된다.
이렇게 생성된 임시 객체는 다음 행으로 넘어가면 바로 소멸되어 진다. 단, 참조자에 의해 참조될 경우 그 임시 객체는 바로 소멸되지 않는다.
- 참고
클래스 외부에서 객체의 멤버 함수를 호출하기 위해 필요한 것.
객체에 붙여진 이름, 객체의 참조 값(객체 참조에 사용되는 정보), 객체의 주소 값
'컴퓨터 언어 정리 > C++ 언어' 카테고리의 다른 글
| 17 상속 (0) | 2020.09.14 |
|---|---|
| 16 friend, static, const, mutable (0) | 2020.09.14 |
| 14 클래스와 배열 및 this 포인터 (0) | 2020.09.13 |
| 13 생성자와 소멸자 (0) | 2020.09.12 |
| 11, 12 정보 은닉과 캡슐화 (0) | 2020.09.11 |