스택을 연결리스트로 구현해 보았다.

일단 기본 구조에 대한 예시를 나타낸 것이다.
먼저, 왼쪽 구조를 보자. 우리 스택이라고 생각하는 구조이다. Head는 삽입 인덱스를 나타낸다. 소위 말하는 top 변수. 그 왼쪽의 구조를 단순화시켜서 보면 오른쪽처럼 나타낼 수 있다. 오른쪽 구조에서 Head 노드는 새롭게 노드가 삽입될 때 마다 가리키는 것을 갱신시키는데, 이 현상을 자세히 보면 왼쪽 구조에서 head가 옮겨다니는 것과 같다.
다른 현상을 가지고 생각하기 나름으로 같은 본질을 끌어냈다 크.. 윤성우 교수님께 박수를...
암튼 왼쪽이든 오른쪽이든 위와 같은 본질의 구조를 구현할 것이다.
삽입 연산

1) 헤드와 기존 최 상단 노드의 연결을 끊고, 2) 새 노드와 최상단 노드를 연결하여 새 노드를 최상단 노드로 변경하고, 그 3) 최상단 노드를 헤드가 가리키도록 헤드 값을 갱신
삭제 연산

삭제의 기본 동작은 노란색 글씨와 빨간색 글씨로 표현을 해두었다.
파란색 글씨는 대충 이런 말이다. 할당된 메모리는 따로 이전에 만들어 뒀던 자료구조로 따로 저장하여 관리하고 프로그램 종료 시, 일괄로 삭제하기 때문에 관련 포인터만 변경하고(모든 포인터 연결을 삭제 '처리') 삭제 되었다고 생각하고 진행하라는 의미이다.
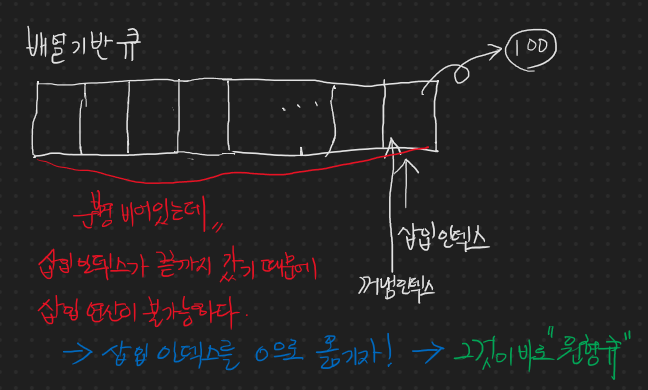
비어짐 확인

이런 구조에서 비어짐을 확인하려면 어떻게 하면 될까?
> Head가 NULL을 가리키면 텅 빈 상태입니다. (O)
이런 구조에서 꽉 참을 확인하려면 어떻게 하면 될까?
> 연결 리스트 기반이라 꽉 찰 것을 걱정하지 않아도 됩니다.(O) 그 걱정대신 작성자 나이 걱정을.... (ㅜ.ㅜ)
뭐 더 쓸 말이 없다.
코드 및 실행 결과
프로그램 코드를 제출하기에 앞서 복습도 할 겸,
이전에 배웠던 원형 큐를 활용하여 메모리가 생성될 때마다 원형 큐에 메모리 주소를 넣고, 프로그램이 종료될 때 일괄적으로 free~~~~~~~ 된다. 그니까 생성만 했다하면 원형 큐에 넣어제끼고, 프로그램이 끝나기 직전에 다 소멸시켜버리는 것이다. 그래서 실행 결과가 지저분하여 실행결과도 약간의 설명을 넣을 예정이다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
|
#include <stdio.h>
#include <stdlib.h>
#define QUEUE_LEN 11
#define TRUE 1
#define FALSE 0
struct node
{
int data;
struct node* next;
};
struct list_stack
{
struct node* head;
int count;
};
typedef struct list_stack stack;
/////////////////////////// 건들지 않아도 될 큐 부분(포스팅을 위해 모듈로 나누지 않는다) ///////////////////////////
struct array_queue // 배열 기반 원형 큐 구현
{
int front;
int rear;
int count;
struct node* queue_array[QUEUE_LEN];
};
typedef struct array_queue queue;
void QueueInit(queue* q);
int QisEmpty(queue* q);
struct node* Dequeue(queue* q);
void Enqueue(queue* q, struct node* data);
void ShowQueue(queue* q);
/////////////////////////// 건들지 않아도 될 큐 부분(포스팅을 위해 모듈로 나누지 않는다) ///////////////////////////
void RemoveAllNodeAuto(queue* q);
struct node* CreateNodeAuto(stack* s, queue* q);
// list stack
void StackInit(stack* s);
int SIsEmpty(stack* s);
void SPush(stack* s, queue* q, int data);
int SPop(stack* s, queue* q);
int SPeek(stack* s);
int main(void)
{
stack s;
queue q;
QueueInit(&q);
StackInit(&s);
SPush(&s, &q, 1);
SPush(&s, &q, 2);
SPush(&s, &q, 3);
SPush(&s, &q, 4);
SPush(&s, &q, 5);
while (!SIsEmpty(&s))
printf("%d ", SPop(&s, &q));
fputc('\n', stdout);
ShowQueue(&q);
printf("----------------------------------------------------------\n");
RemoveAllNodeAuto(&q);
return 0;
}
/////////////////////////// 건들지 않아도 될 큐 부분(포스팅을 위해 모듈로 나누지 않는다) ///////////////////////////
void QueueInit(queue* q)
{
int i = 0;
q->front = q->rear = 0;
for (i = 0; i < QUEUE_LEN; i++)
q->queue_array[i] = NULL; // 큐 출력을 위한 초기화
q->count = 0;
return;
}
int QisEmpty(queue* q)
{
if (q->front == q->rear)
return TRUE;
else
return FALSE;
}
struct node* Dequeue(queue* q)
{
struct node* target;
// 기본 동작 - 비었는가 확인 -> 삭제 -> 인덱스 변경
if (q->front == q->rear)
{
printf("Queue가 이미 비었습니다.\n");
return NULL;
}
target = q->queue_array[q->front];
q->queue_array[q->front] = NULL;
q->front = (q->front + 1) % QUEUE_LEN;
return target;
}
void Enqueue(queue* q, struct node* data)
{
// 기본 동작 - 꽉 찼는가 확인 -> 삽입 -> 인덱스 변경
if ((q->rear + 1) % QUEUE_LEN == q->front) // 가득 찬 경우,
{
printf("Queue가 가득 찼습니다.\n");
return;
}
q->queue_array[q->rear] = data;
q->rear = (q->rear + 1) % QUEUE_LEN;
q->count++;
return;
}
void ShowQueue(queue* q)
{
int i = 0;
printf("{(r:%2d/f:%2d)} : ", q->rear, q->front);
for (i = 0; i < QUEUE_LEN; i++)
printf("[%2p]", q->queue_array[i]), putc('-', stdout);
putc('\n', stdout);
return;
}
/////////////////////////// 건들지 않아도 될 큐 부분(포스팅을 위해 모듈로 나누지 않는다) ///////////////////////////
// 내가 정의하는 함수
struct node* CreateNodeAuto(stack* s, queue* q)
{
struct node* tmp = (struct node*)malloc(sizeof(struct node));
// 초기화
tmp->data = 0;
tmp->next = NULL; // tmp->next = s->head;
// 큐 추가
Enqueue(q, tmp);
return tmp;
}
void RemoveAllNodeAuto(queue* q)
{
struct node* rtarget = NULL;
while (!QisEmpty(q))
{
rtarget = Dequeue(q);
printf("[%p/(%d)]가 제거되었습니다.\n", rtarget, q->count);
ShowQueue(q);
free(rtarget);
q->count--;
}
return;
}
// list stack
void StackInit(stack* s)
{
s->count = 0;
s->head = NULL;
return;
}
int SIsEmpty(stack* s)
{
if (s->head == NULL)
return TRUE;
else
return FALSE;
}
void SPush(stack* s, queue* q, int data)
{
// 추가해야할 새로운 노드 생성
struct node* newnode = CreateNodeAuto(s, q);
// 새로운 노드의 값 세팅 및 기존 노드로 next 연결
newnode->data = data;
newnode->next = s->head;
// head를 새로운 노드와 연결
s->head = newnode;
// count 증가
s->count++;
return;
}
int SPop(stack* s, queue* q)
{
struct node* target = s->head;
// head 가 Null을 가리키고 있다면 스택이 비어있는 것. 조건 검사 진행
if (SIsEmpty(s))
{
printf("스택이 이미 비어있습니다\n");
return 0;
}
// head 를 target의 next, 다음 노드와 연결한다.
s->head = target->next;
// count 감소
s->count--;
return target->data;
}
int SPeek(stack* s)
{
if (SIsEmpty(s))
{
printf("스택이 이미 비어있습니다\n");
return 0;
}
return s->head->data;
}
|
cs |
혹시 보는 사람이 있다면 스택 부분만 참고하면 될 듯 합니다. 앞으로도 쭉 요래요..ㅋㅋ

'프로그래밍응용 > C 자료구조' 카테고리의 다른 글
| C Data Structure - 리스트 기반 큐 (0) | 2021.01.20 |
|---|---|
| C Data Structure - 원형 양방향 연결 리스트 (0) | 2021.01.19 |
| C Data Structure - 스택 (0) | 2021.01.18 |
| C Data Structure - 원형 큐 (0) | 2021.01.15 |
| C Data Structure - 큐 (0) | 2021.01.08 |