C++은 다른 언어들처럼 가비지 컬렉터가 없다ㅋㅋ 그래서 메모리 관리를 제대로 하지 않으면, 정확히 Heap 영역에 대한 메모리 관리가 제대로 되지 않는다면,
헬이다. 헬.
그러면 어찌해야하는가? RAII 라는 디자인 패턴이 있다.
Resource Acquisition Is Initialization
위를 줄여서 RAII 라고 부른다.
RAII의 유래
그럼 왜 RAII일까? 유래를 좀 찾아봤는데 자원의 획득은 초기화이고, 반대로 자원의 반환은 객체 소멸 뭐 이런 식으로 확장하여 나타내는 어떤 관용구 같은 느낌의 디자인 패턴 개념이다.
RAII란?
좀 더 자세하게 관련해서 정의를 알아 보자면 RAII 는 객체의 생명주기에 관련된 내용으로, C++에서 객체가 생성되고 사용된 Scope를 벗어나면 객체의 자원을 해제해주는 방법을 이야기한다.
즉, 힙에 동적 할당되는 객체라고 해도, 프로그램 실행 흐름이 해당 객체의 유효 scope를 벗어나면 객체를 메모리 해체하도록 하는 것이 RAII라고 생각하면 될 것 같다.
근데 아쉽게도 힙 영역에 할당된 객체는 지역 scope를 벗어난다고해서 동적할당된 부분이 해체되지 않는다. 왜냐하면 동적할당이 이루어지는 해당 scope 내에는 객체 포인터가 스택에 쌓이고, 해당 scope가 끝나면 그 객체 포인터만 스택에서 소멸된다. 동적할당된 메모리는 힙 영역에 그대로 남아있다.
다음과 같이 말이다.

위의 사실을 응용하여,
어떤 scope에서 동적 할당이 이루어졌다면, 해당 scope에서 스택 영역에 할당되는 요소에게 동적 할당한 주소를 넘겨주고, 그 스택 영역에 할당된 요소는 스택에서 제거될 때, 넘겨받은 동적 할당된 주소를 함께 delete 하면서 제거되면 되지 않을까? 라는 발상이 떠오른다. 아래와 같이 말이다.

문제가 되는 부분
자, 일단은 문제가 되는 코드이다. 위의 그림과는 살짝 다르지만 문제 없다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
#include <iostream>
class R
{
private:
int *data;
public:
R(int len)
{
this->data = new int[len];
std::printf("R() call! : new int[%d]\n",len);
}
~R()
{
delete []this->data;
std::printf("~R() call! : delete [] \n");
}
};
void function(void)
{
R * r = new R(1000);
std::printf("function() 함수 종료\n");
return;
}
int main(void)
{
function();
return 0;
}
|
cs |
위의 코드에서 function 함수라는 지역 scope 내에서 객체 R을 동적할당하고, function 함수를 그냥 종료하는 모습이다. 동적 할당된 R 은 소멸되지 않고 그대로 남다가 해당 프로세스가 종료될 때, 비로소 운영체제에 의해서 메모리 자원이 회수된다. 이런 회수를 원한게 아닌데 말이다.
그렇다면 실행 결과를 보자.
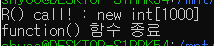
분명히, 소멸자가 호출되지 않은 모습이다. 이것이 바로 메모리 누수(Leak)
스마트 포인터
이를 해결할 방법으로 스마트 포인터라는 것이 등장한다. 포인터 역할을 하는 객체로 이 스마트 포인터를 스택 객체로 할당하고 동적 할당 주소를 넘겨주면 스마트 포인터 객체가 소멸될 때 동적 할당된 힙까지 알아서 똑똑하게 삭제를 해주기 때문이다.
이러한 스마트 포인터를 직접 구현해보았다. 다른 이미 구현된 스마트 포인터만큼 스마트하지는 못해서 그냥 오토 포인터라고 이름을 지었다ㅋㅋㅋ
뭐 아래의 연산자 오버로딩 포스팅 때, 구현을 이미 해봤지만 그래도 새롭게 참고하면서 구현해보았다.
21 연산자 오버로딩
연산자 오버로딩 연산자 오버로딩 C++언어에서는 연산자의 오버로딩을 통해서 기존에 존재하던 연산자의 기본 기능 이외에 다른 기능을 추가할 수 있다. 먼저 15번 라인을 통해서 operator+ 라는 함
typingdog.tistory.com
코드 및 실행결과
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
|
#include <iostream>
class R
{
private:
int* data;
int len;
public:
R(int _len)
{
this->len = _len;
this->data = new int[_len];
for (int i = 0; i < _len; i++)
this->data[i] = i * 100000;
std::printf("R() call! : new int[%d]\n", _len);
}
~R()
{
delete[]this->data;
std::printf("~R() call! : delete [] \n");
}
void ShowData(void) const
{
for (int i = 0; i < this->len; i++)
std::printf("%d, ", this->data[i]);
std::cout << std::endl;
return;
}
};
template <typename T>
class AutoPointer
{
private:
const T* ptr;
public:
AutoPointer(T* _ptr) : ptr(_ptr)
{
}
~AutoPointer()
{
delete this->ptr;
}
const T& operator* () const
{
return *(this->ptr);
}
const T* operator-> () const
{
return this->ptr;
}
};
void function(void)
{
AutoPointer<R> r(new R(10));
r->ShowData();
std::printf("function() 함수 종료!\n");
return;
}
int main(void)
{
function();
return 0;
}
|
cs |

이렇게 힘들게 만들었는데 이미 C++ 11에서는 다음과 같은 문법을 제공한다.
unique_ptr<> : #include <memory>
이미 11 문법에서는 겁나 스마트한 포인터 객체로 제공을 해주었던 것이다... 사용 방법은 내가 만든 오토 포인터와 같으니 바로 예제로 들어가보겠다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
#include <iostream>
#include <memory>
class R
{
private:
int *data;
public:
R(int len)
{
this->data = new int[len];
std::printf("R() call! : new int[%d]\n",len);
}
~R()
{
delete []this->data;
std::printf("~R() call! : delete [] \n");
}
};
void function(void)
{
std::unique_ptr<R> r(new R(1000));//R * r = new R(1000);
std::printf("function() 함수 종료\n");
return;
}
int main(void)
{
function();
return 0;
}
|
cs |

불안정한 메모리 관리를 이러한 패턴으로 처리한다는게 정말 잔머리를? 기가막히게 잘 굴린듯한 느낌이다. 그래도 GC(가비지 컬렉터)가 제공되면 참 좋겠지만 이렇게라도 일부라도 관리를 틈틈이 하는게 좋은 것 같다.
다음 번 포스팅에서는 (공부하다가 필요한 부분부분 정리하는 포스팅이기 때문에 시리즈물처럼 바로 다음 번은 아니지만) 이 unique_ptr 외에 공유 가능한, 그리고 인자로의 전달 시 어떤 형태로 코드를 짜야하는 지 등에 대해서 올려볼 것이다.
'프로그래밍응용 > Modern & STL' 카테고리의 다른 글
| 멀티 쓰레딩 지원 (0) | 2021.02.10 |
|---|---|
| 함수 포인터를 대체하는 std::function (0) | 2021.02.08 |
| Lambda Expression (0) | 2021.01.27 |
| R-Value, Copy Elision, 이동 생성자, RVO, NRVO (0) | 2021.01.26 |
| 자료형 추론 auto / 범위 기반 for (0) | 2021.01.21 |