오늘은 덱? 디큐? 라고 불리우는 자료구조이다.
Dequeue 는 매우 혼종이다. 큐라고는 불리우는데 큐의 특징 이외에 스택의 특징을 가지고 있기 때문이다. 선입선출 / 후입선출 등의 개념을 모두 가지고 있다. 먼저 들어온 놈이 먼저 나갈 수 있고, 나중에 들어온 놈이 먼저 나갈 수도 있다는 것이다.
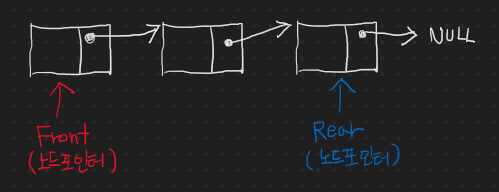
도데체 어떤 구조이길래 위와 같은 특징을 가지고 있을까? 다음과 같다.

위와 같은 구조이다. 뒤에서도 (tail의 사이드) 추가 및 삭제가 가능해야 하기 때문에 꼭 양방향 링크로 구성이 되어야 한다!!!!!
그런데 뭐, 이제까지 다 다뤄봤던 구조들이기 때문에 예를 들어, 양방향 링크라든지 head와 tail이 함께 있는 구조라든지 어렵지 않은 부분들이므로 간단하게 설명한다.
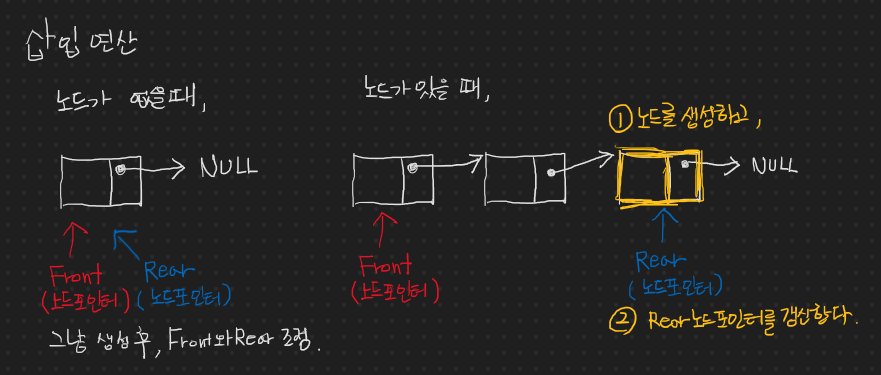
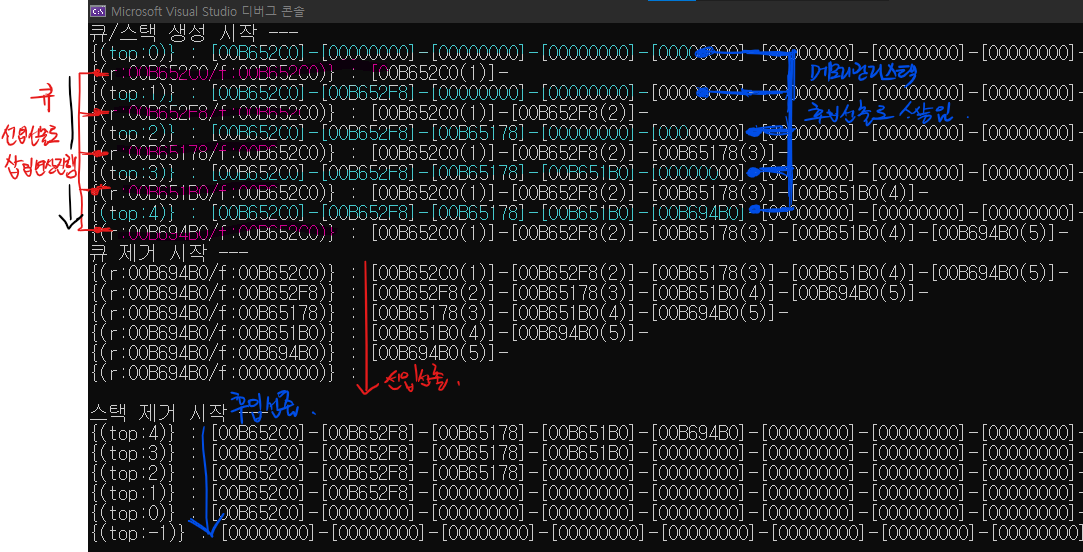
초기화와 Dequeue의 비워짐 / 꽉 참의 확인
먼저, 초기화는 Head와 Tail 을 NULL로 초기화 하는 것으로 시작한다.
그리고 이러한 초기화에 따라서, Head와 Tail이 NULL 인 경우가 비워진 경우이고, 해당 Dequeue의 꽉 찬 상태는 확인할 필요가 없다. 왜냐하면 연결 기반의 큐이기 때문에 추가하는 수의 제한이 없다고 보면 되기 때문이다.
노드 추가

위 그림으로 설명이 충분하다고 생각한다. 노란색이 추가되는 노드이고, head와 tail 은 각각 옮겨가는 것을 표현한 것이다.
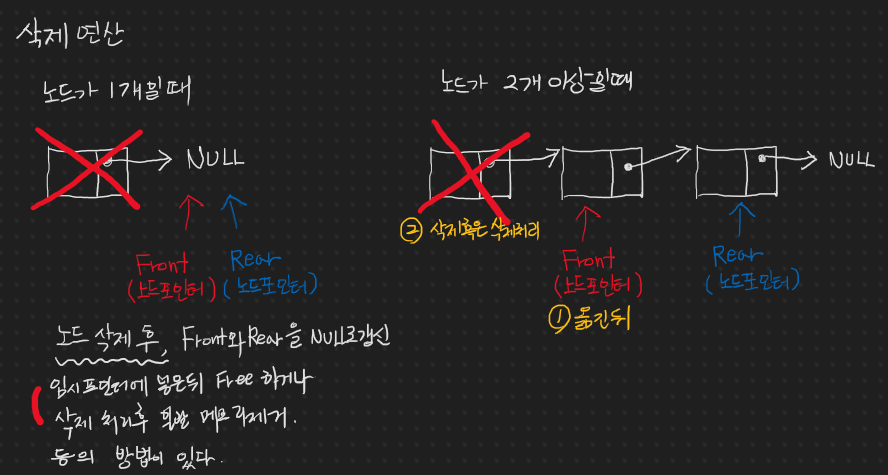
노드 삭제

노드 그림을 그리지 않고 코드로만 설명해도 되겠다고 판단하여 그림을 그리지 않는다. 코드의 주석만으로 충분한 설명이 되었다고 본다.
탐색
탐색은 다른 리스트들과 마찬가지로 링크들을 타면서 순회하는 것이기 때문에 딱히 구현하지 않았다.
메모리 관리
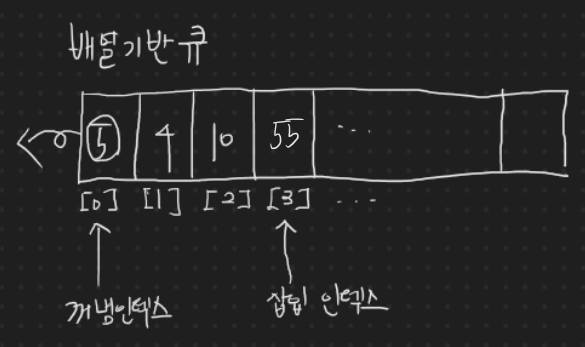
배열 기반의 원형 큐를 통해 메모리 관리를 한다.
소스 코드 및 실행 결과
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
|
#include <stdio.h>
#include <stdlib.h>
#define QUEUE_LEN 11
#define TRUE 1
#define FALSE 0
struct node
{
int data;
struct node* prev;
struct node* next;
};
struct list_dequeue
{
struct node* head;
struct node* tail;
int count;
};
typedef struct list_dequeue dequeue;
struct array_queue // 배열 기반 원형 큐 구현
{
int front;
int rear;
int count;
struct node* queue_array[QUEUE_LEN];
};
typedef struct array_queue queue;
void QueueInit(queue* q);
int QisEmpty(queue* q);
struct node* Dequeue(queue* q);
void Enqueue(queue* q, struct node* data);
void ShowQueue(queue* q);
void RemoveAllNodeAuto(queue* q);
struct node* CreateNodeAuto(dequeue* dq, queue* q);
void DequeueInit(dequeue* dq)
{
// head와 tail을 NULL로 초기화
dq->head = NULL;
dq->tail = NULL;
// count 값을 0으로 초기화
dq->count = 0;
return;
}
int DQIsEmpty(dequeue* dq)
{
if (dq->head == NULL && dq->tail == NULL) // head와 tail이 동일하게 NULL을 가리킨다면 true 반환
return TRUE;
else // 아니면 false 반환
return FALSE;
}
void DQAddFirst(dequeue* dq, queue* q, int data)
{
// 새 노드 생성 -> prev와 next는 모두 NULL
struct node* newnode = CreateNodeAuto(dq, q);
newnode->data = data;
if (DQIsEmpty(dq)) // 비어있다면 head와 tail에게 새 노드 주소를 던짐
{
dq->head = dq->tail = newnode;
}
else // 안 비어있다면 next는 원래 head가 가리키고 있던 주소, head만 변경.
{
newnode->next = dq->head;
dq->head->prev = newnode;
dq->head = newnode;
}
// count 증가
dq->count++;
return;
}
void DQAddLast(dequeue* dq, queue* q, int data)
{
// 새 노드 생성 -> prev와 next는 모두 NULL
struct node* newnode = CreateNodeAuto(dq, q);
newnode->data = data;
if (DQIsEmpty(dq)) // 비어있다면 head와 tail에게 새 노드 주소를 던짐
{
dq->head = dq->tail = newnode;
}
else // 안 비어있다면 prev는 원래 tail이 가리키고 있던 주소, tail만 변경.
{
newnode->prev = dq->tail;
dq->tail->next = newnode;
dq->tail = newnode;
}
// count 증가
dq->count++;
return;
}
int DQRemoveFirst(dequeue* dq)
{
struct node* target = NULL;
int data = 0;
if (DQIsEmpty(dq)) // 비어있다면 x
{
printf("dequeue가 이미 비어져 있습니다.\n");
return -1;
}
// 비어있지 않으면 현재 head를 임시 변수에 저장
target = dq->head;
// head를 현재 head의 next로 옮긴다
dq->head = dq->head->next;
// 임시 변수에서 값 추출
data = target->data;
// 카운트를 감소한다.
dq->count--;
// 변경된 헤드가 NULL인지 확인한다.
if (dq->head == NULL)
{
dq->tail = NULL;
}
else
{
dq->head->prev = NULL;
}
// 메모리 해체는 원형 큐에서.
return data;
}
int DQRemoveLast(dequeue* dq)
{
struct node* target = NULL;
int data = 0;
if (DQIsEmpty(dq)) // 비어있다면 x
{
printf("dequeue가 이미 비어져 있습니다.\n");
return -1;
}
// 비어있지 않으면 현재 tail을 임시 변수에 저장
target = dq->tail;
// tail을 현재 tail의 prev로 옮긴다
dq->tail = dq->tail->prev;
// 임시 변수에서 값 추출
data = target->data;
// 카운트를 감소한다.
dq->count--;
// 변경된 헤드가 NULL인지 확인한다.
if (dq->tail == NULL)
{
dq->head = NULL;
}
else
{
dq->tail->next = NULL;
}
// 메모리 해체는 원형 큐에서.
return data;
}
int DQGetFirst(dequeue* dq)
{
// 비어있다면 x
if (DQIsEmpty(dq))
{
printf("dequeue가 이미 비어져 있습니다.\n");
return -1;
}
// 비어있지 않으면 현재 head의 값을 리턴
return dq->head->data;
}
int DQGetLast(dequeue* dq)
{
// 비어있다면 x
if (DQIsEmpty(dq))
{
printf("dequeue가 이미 비어져 있습니다.\n");
return -1;
}
// 비어있지 않으면 현재 tail의 값을 리턴
return dq->tail->data;
}
void ShowDequeue(dequeue* dq)
{
struct node* dq_index = NULL;
for (dq_index = dq->head; dq_index != NULL; dq_index = dq_index->next)
printf("[%p/%d] - ", dq_index, dq_index->data);
fputc('\n', stdout);
return;
}
int main(void)
{
queue q;
dequeue dq;
QueueInit(&q);
DequeueInit(&dq);
DQAddFirst(&dq, &q, 2); ShowDequeue(&dq); // ShowQueue(&q);
DQAddFirst(&dq, &q, 1); ShowDequeue(&dq); // ShowQueue(&q);
DQAddFirst(&dq, &q, 3); ShowDequeue(&dq); // ShowQueue(&q);
DQAddLast(&dq, &q, 4); ShowDequeue(&dq); //ShowQueue(&q);
DQAddLast(&dq, &q, 5); ShowDequeue(&dq); //ShowQueue(&q);
DQAddLast(&dq, &q, 6); ShowDequeue(&dq); //ShowQueue(&q);
printf("----- 1\n");
while (!DQIsEmpty(&dq))
printf("%d ", DQRemoveFirst(&dq));
fputc('\n', stdout);
RemoveAllNodeAuto(&q);
DQAddFirst(&dq, &q, 3);
DQAddFirst(&dq, &q, 2);
DQAddFirst(&dq, &q, 1);
DQAddLast(&dq, &q, 4);
DQAddLast(&dq, &q, 5);
DQAddLast(&dq, &q, 6);
printf("----- 2\n");
while (!DQIsEmpty(&dq))
printf("%d ", DQRemoveLast(&dq));
fputc('\n', stdout);
RemoveAllNodeAuto(&q);
// 6 5 3 1 2 4 7 8
DQAddFirst(&dq, &q, 1);
DQAddLast(&dq, &q, 2);
DQAddFirst(&dq, &q, 3);
DQAddLast(&dq, &q, 4);
DQAddFirst(&dq, &q, 5);
DQAddFirst(&dq, &q, 6);
DQAddLast(&dq, &q, 7);
DQAddLast(&dq, &q, 8);
printf("----- 3\n");
while (!DQIsEmpty(&dq))
printf("%d ", DQRemoveFirst(&dq));
fputc('\n', stdout);
RemoveAllNodeAuto(&q);
return 0;
}
///// MEMORY QUEUE
void QueueInit(queue* q)
{
int i = 0;
q->front = q->rear = 0;
for (i = 0; i < QUEUE_LEN; i++)
q->queue_array[i] = NULL; // 큐 출력을 위한 초기화
q->count = 0;
return;
}
int QisEmpty(queue* q)
{
if (q->front == q->rear)
return TRUE;
else
return FALSE;
}
struct node* Dequeue(queue* q)
{
struct node* target;
// 기본 동작 - 비었는가 확인 -> 삭제 -> 인덱스 변경
if (q->front == q->rear)
{
printf("Queue가 이미 비었습니다.\n");
return NULL;
}
target = q->queue_array[q->front];
q->queue_array[q->front] = NULL;
q->front = (q->front + 1) % QUEUE_LEN;
return target;
}
void Enqueue(queue* q, struct node* data)
{
// 기본 동작 - 꽉 찼는가 확인 -> 삽입 -> 인덱스 변경
if ((q->rear + 1) % QUEUE_LEN == q->front) // 가득 찬 경우,
{
printf("Queue가 가득 찼습니다.\n");
return;
}
q->queue_array[q->rear] = data;
q->rear = (q->rear + 1) % QUEUE_LEN;
q->count++;
return;
}
void ShowQueue(queue* q)
{
int i = 0;
printf("{(r:%2d/f:%2d)} : ", q->rear, q->front);
for (i = 0; i < QUEUE_LEN; i++)
printf("[%2p]", q->queue_array[i]), putc('-', stdout);
putc('\n', stdout);
return;
}
// 내가 정의하는 함수
struct node* CreateNodeAuto(dequeue* dq, queue* q)
{
struct node* tmp = (struct node*)malloc(sizeof(struct node));
// 초기화
tmp->data = 0;
tmp->prev = NULL;
tmp->next = NULL; // tmp->next = s->head;
// 큐 추가
Enqueue(q, tmp);
return tmp;
}
void RemoveAllNodeAuto(queue* q)
{
struct node* rtarget = NULL;
ShowQueue(q);
while (!QisEmpty(q))
{
rtarget = Dequeue(q);
printf("[%p/(%d)]가 제거되었습니다.\n", rtarget, q->count);
ShowQueue(q);
free(rtarget);
q->count--;
}
return;
}
|
cs |

'프로그래밍응용 > C 자료구조' 카테고리의 다른 글
| C Data Structure - 이진 탐색 트리 2 (0) | 2021.01.24 |
|---|---|
| C Data Structure - 이진 탐색 트리 1 (0) | 2021.01.23 |
| C Data Structure - 리스트 기반 큐 (0) | 2021.01.20 |
| C Data Structure - 원형 양방향 연결 리스트 (0) | 2021.01.19 |
| C Data Structure - 연결 리스트 기반 스택 (0) | 2021.01.19 |