스택이란 정말 간단하다.
분명히 내가 이거 그림 그리면서 포스팅을 한거 같은데 아무리 블로그를 뒤져봐도 없다... 그래서 다시 하는 느낌으로 스택 첫 포스팅을 시작한다.
먼저,
스택이란 무엇인가?

우리는 스택을 이미 알고 있다. 스택은 프링글스이다. 아래의 그림을 보자.

우리는 세 개의 감자칩 중에서 어떤 감자칩이 제일 먼저 들어갔는지 알 수 있다. 바로 A이다. 어떻게 알았지? 출입구가 하나이고, 원통 내부의 크기는 서로가 뭐 어떻게 비집고 해서 바꿀 수 있는 사이즈가 아니다.
A가 먼저 들어갔고 -> 그 다음 B가 그 위에 쌓이고 -> 그 후 C가 들어가면서 그 위에 쌓이는 것이다.
이렇듯 스택은 쌓이는 특징을 가지고 있다. 그렇다면 안의 감자칩을 꺼내먹을 때에는 어떻게 할까?
가장 나중에 들어간 C가 제일 먼저 다시 나오고 -> 그 다음 B가 나오고 -> 가장 먼저 들어간 A가 제일 늦게 나온다.
이렇게 나중에 들어간 값이 제일 먼저 나오는 구조를 후입선출 구조라고 한다.
단순 배열 기반 스택에서의 삽입
어려울 것이 전혀 없다. 그냥 값이 들어오는데로 쌓아올린다고 생각하고 인덱스를 증가시키면서 값을 추가하면 된다.


하나도 어렵지 않다. 이렇게 보면 그냥 배열 끝에 값을 추가하는 것 같다. 우리는 스택에 값을 추가하는 행위를 push 라고 할 것이다. 삭제 연산을 보자.
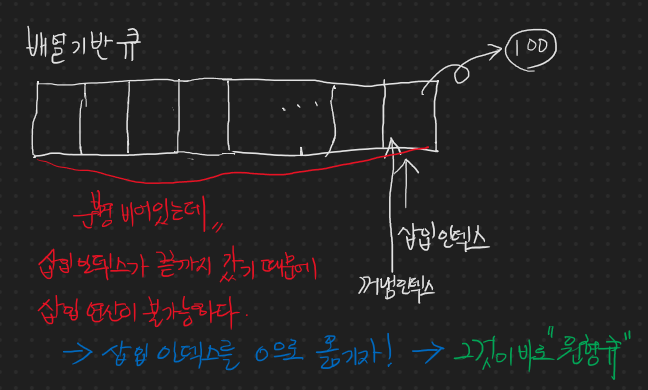
단순 배열 기반 스택에서의 삭제

3 값이 튀어나가면서 삭제 처리가 되어 버리고, 삽입 인덱스가 하나 감소한다.

마지막 하나 남은 1이 튀어 나가며 값이 삭제 처리 되고, 삽입 인덱스가 갈 곳을 잃는데 이 때, 삽입 인덱스를 -1로 하자. 그러면 나중에 빈 스택 상태에서 값을 추가할 때, 삽입 인덱스를 증가시키면 [-1] 에서 [0]으로 바뀌어서 자연스럽게 값을 추가하면 될 뿐만 아니라, 스택이 비어있는지 비어있지 않는지 삽입 인덱스가 -1인지 아닌지를 보면 된다.
그리고 우리는 삭제하는 연산을 pop 한다고 할 것이다.
단순 배열 기반 스택에서의 비워짐과 꽉참을 확인


또한 간단하다.
인덱스가 비워져 있는지를 확인하기 위해선 아까 삭제 연산에의 약속대로 삽입 인덱스가 -1인지를 확인하면 된다.
인덱스가 가득차 있는지를 확인하기 위해선 현재 삽입 인덱스가 배열의 길이랑 같은지를 확인하면 된다.
코드 및 실행 결과
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
|
#include <stdio.h>
#define STACK_LEN 10
#define TRUE 1
#define FALSE 0
struct array_stack
{
int stack_arr[STACK_LEN];
int top_index;
};
typedef array_stack stack;
void StackInit(stack* s);
int SIsEmpty(stack* s);
void SPush(stack* s, int data);
int SPop(stack* s);
int SPeek(stack* s);
int main(void)
{
stack s;
StackInit(&s);
SPush(&s, 1);
SPush(&s, 2);
SPush(&s, 88);
SPush(&s, 125);
SPush(&s, 9912);
while (!SIsEmpty(&s))
printf("[%d] ", SPop(&s));
fputs("\n", stdout);
if (SIsEmpty(&s))
printf("스택이 텅 비었습니다.\n");
return 0;
}
void StackInit(stack* s)
{
s->top_index = -1;
return;
}
int SIsEmpty(stack* s)
{
if (s->top_index == -1) // 같아도 된다고?
return TRUE;
else
return FALSE;
}
void SPush(stack* s, int data)
{
if (s->top_index == STACK_LEN)
{
printf("스택이 꽉 찼습니다.\n");
return;
}
s->stack_arr[++(s->top_index)] = data;
printf("스택에 %d 값이 추가 되었습니다.\n", s->stack_arr[s->top_index]);
return;
}
int SPop(stack* s)
{
if (SIsEmpty(s))
{
printf("스택이 이미 비어져 있습니다.\n");
return -1; // 적절치 않다. -1 또한 값으로 넣을 수 있기 때문에. -> 차라리 프로그램을 종료시키는게 적절.
}
return s->stack_arr[s->top_index--];
}
int SPeek(stack* s)
{
if (SIsEmpty(s))
{
printf("스택이 텅 비었습니다.\n");
return -1;
}
return s->stack_arr[s->top_index];
}
|
cs |

'프로그래밍응용 > C 자료구조' 카테고리의 다른 글
| C Data Structure - 원형 양방향 연결 리스트 (0) | 2021.01.19 |
|---|---|
| C Data Structure - 연결 리스트 기반 스택 (0) | 2021.01.19 |
| C Data Structure - 원형 큐 (0) | 2021.01.15 |
| C Data Structure - 큐 (0) | 2021.01.08 |
| C Data Structure - 퀵 정렬 (0) | 2021.01.06 |