#include <iostream>
#include <stack>
#include <stdio.h>
using namespace std;
// 구조체 존
struct node {
int data;
struct node* prev;
struct node* next;
};
struct list {
struct node* head;
struct node* ci; // current index
int count;
};
// 클래스 존
class NodeMemoryManager // 이 클래스 자체에 템플릿을 때려버리면 여러 타입에 대해서 관리할 수 있다ㅋ
{
private:
int count; // 내부적인 교차 검증을 위한 count;
stack<struct node*> allocated_node_address;
public:
NodeMemoryManager()
{
this->count = 0;
}
~NodeMemoryManager()
{
int free_count = 0;
int stack_count = this->allocated_node_address.size(); // 제거하기 전 숫자.
// 스택은 내부적으로 벡터니까 -> 임의 접근이 되지 않을까? -> 불가능 -> 그럴거면 벡터를 쓰지 왜 스택을 쓰나? 스택의 탄생 이유이다.
while (!this->allocated_node_address.empty())
{
free(this->allocated_node_address.top()); // c에서 malloc 할 것이니, free 함수.
this->allocated_node_address.pop();
free_count++;
}
cout << "모든 메모리가 해체되었습니다[" << free_count << "/" << this->count << "(" << stack_count << ")]" << endl;
}
struct node* CreateNodeAuto(void)
{
struct node* tmp = (struct node*)malloc(sizeof(struct node));
// 초기화
tmp->data = 0;
tmp->prev = NULL;
tmp->next = NULL;
// 스택 추가
this->AddAllocatedNodeAddress(tmp);
return tmp;
}
void AddAllocatedNodeAddress(struct node* addr)
{
this->allocated_node_address.push(addr);
this->count++;
return;
}
int GetCount()
{
return this->count;
}
int GetCountByStack()
{
return this->allocated_node_address.size();
}
};
// 재정의 존
typedef struct list List;
// 함수 선언 존
void ListInit(List* list);
void LInsert(List* list, int data);
int LFirst(List* list, int* data);
int LNext(List* list, int* data, int non_exit);
int LPrevious(List* list, int* data, int non_exit);
void LRemove(List* list);
// 전역 변수 존
NodeMemoryManager nmm;
//메인 함수
int main(void)
{
List list;
int data;
ListInit(&list);
// 값 1 ~ 값 8 까지 추가.
LInsert(&list, 1); LInsert(&list, 2); LInsert(&list, 3); LInsert(&list, 4); LInsert(&list, 5); LInsert(&list, 6); LInsert(&list, 7); LInsert(&list, 8);
LFirst(&list, &data);
// 한 칸 씩 이동
printf("-------- previous zone \n");
(LPrevious(&list, &data, 1) == 1) ? printf("[%d]\n", data) : printf("LFirst가 실행되지 않았습니다.\n");
(LPrevious(&list, &data, 1) == 1) ? printf("[%d]\n", data) : printf("LFirst가 실행되지 않았습니다.\n");
(LPrevious(&list, &data, 1) == 1) ? printf("[%d]\n", data) : printf("LFirst가 실행되지 않았습니다.\n");
(LPrevious(&list, &data, 1) == 1) ? printf("[%d]\n", data) : printf("LFirst가 실행되지 않았습니다.\n");
(LPrevious(&list, &data, 1) == 1) ? printf("[%d]\n", data) : printf("LFirst가 실행되지 않았습니다.\n");
(LPrevious(&list, &data, 1) == 1) ? printf("[%d]\n", data) : printf("LFirst가 실행되지 않았습니다.\n");
(LPrevious(&list, &data, 1) == 1) ? printf("[%d]\n", data) : printf("LFirst가 실행되지 않았습니다.\n");
(LPrevious(&list, &data, 1) == 1) ? printf("[%d]\n", data) : printf("LFirst가 실행되지 않았습니다.\n");
(LPrevious(&list, &data, 1) == 1) ? printf("[%d]\n", data) : printf("LFirst가 실행되지 않았습니다.\n");
(LPrevious(&list, &data, 1) == 1) ? printf("[%d]\n", data) : printf("LFirst가 실행되지 않았습니다.\n");
(LPrevious(&list, &data, 1) == 1) ? printf("[%d]\n", data) : printf("LFirst가 실행되지 않았습니다.\n");
(LPrevious(&list, &data, 1) == 1) ? printf("[%d]\n", data) : printf("LFirst가 실행되지 않았습니다.\n");
(LPrevious(&list, &data, 1) == 1) ? printf("[%d]\n", data) : printf("LFirst가 실행되지 않았습니다.\n");
(LPrevious(&list, &data, 1) == 1) ? printf("[%d]\n", data) : printf("LFirst가 실행되지 않았습니다.\n");
printf("-------- next zone \n");
(LNext(&list, &data, 1) == 1) ? printf("[%d]\n", data) : printf("LFirst가 실행되지 않았습니다.\n");
(LNext(&list, &data, 1) == 1) ? printf("[%d]\n", data) : printf("LFirst가 실행되지 않았습니다.\n");
(LNext(&list, &data, 1) == 1) ? printf("[%d]\n", data) : printf("LFirst가 실행되지 않았습니다.\n");
(LNext(&list, &data, 1) == 1) ? printf("[%d]\n", data) : printf("LFirst가 실행되지 않았습니다.\n");
(LNext(&list, &data, 1) == 1) ? printf("[%d]\n", data) : printf("LFirst가 실행되지 않았습니다.\n");
(LNext(&list, &data, 1) == 1) ? printf("[%d]\n", data) : printf("LFirst가 실행되지 않았습니다.\n");
(LNext(&list, &data, 1) == 1) ? printf("[%d]\n", data) : printf("LFirst가 실행되지 않았습니다.\n");
(LNext(&list, &data, 1) == 1) ? printf("[%d]\n", data) : printf("LFirst가 실행되지 않았습니다.\n");
(LNext(&list, &data, 1) == 1) ? printf("[%d]\n", data) : printf("LFirst가 실행되지 않았습니다.\n");
(LNext(&list, &data, 1) == 1) ? printf("[%d]\n", data) : printf("LFirst가 실행되지 않았습니다.\n");
(LNext(&list, &data, 1) == 1) ? printf("[%d]\n", data) : printf("LFirst가 실행되지 않았습니다.\n");
(LNext(&list, &data, 1) == 1) ? printf("[%d]\n", data) : printf("LFirst가 실행되지 않았습니다.\n");
(LNext(&list, &data, 1) == 1) ? printf("[%d]\n", data) : printf("LFirst가 실행되지 않았습니다.\n");
(LNext(&list, &data, 1) == 1) ? printf("[%d]\n", data) : printf("LFirst가 실행되지 않았습니다.\n");
(LNext(&list, &data, 1) == 1) ? printf("[%d]\n", data) : printf("LFirst가 실행되지 않았습니다.\n");
(LNext(&list, &data, 1) == 1) ? printf("[%d]\n", data) : printf("LFirst가 실행되지 않았습니다.\n");
(LNext(&list, &data, 1) == 1) ? printf("[%d]\n", data) : printf("LFirst가 실행되지 않았습니다.\n");
(LNext(&list, &data, 1) == 1) ? printf("[%d]\n", data) : printf("LFirst가 실행되지 않았습니다.\n");
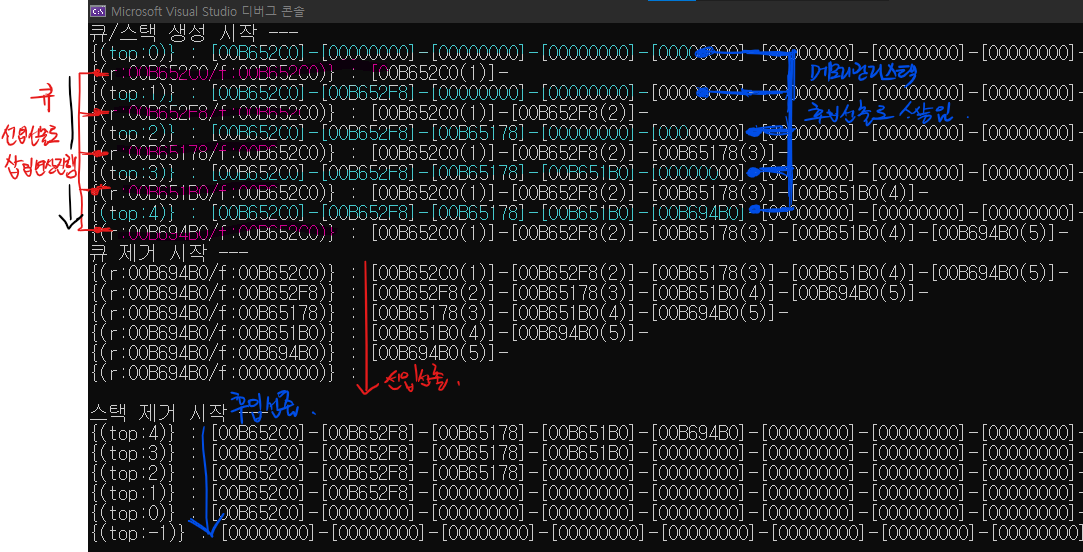
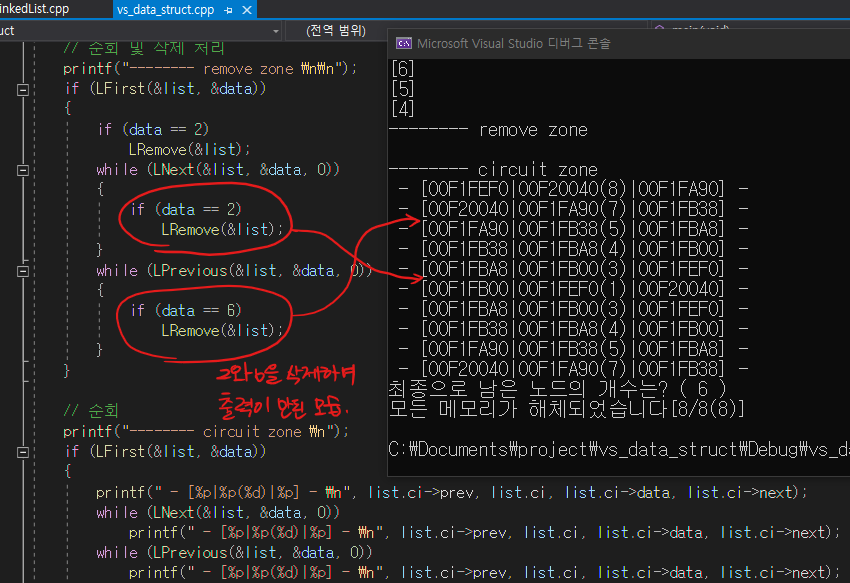
// 순회 및 삭제 처리
printf("-------- remove zone \n\n");
if (LFirst(&list, &data))
{
if (data == 2)
LRemove(&list);
while (LNext(&list, &data, 0))
{
if (data == 2)
LRemove(&list);
}
while (LPrevious(&list, &data, 0))
{
if (data == 6)
LRemove(&list);
}
}
// 순회
printf("-------- circuit zone \n");
if (LFirst(&list, &data))
{
printf(" - [%p|%p(%d)|%p] - \n", list.ci->prev, list.ci, list.ci->data, list.ci->next);
while (LNext(&list, &data, 0))
printf(" - [%p|%p(%d)|%p] - \n", list.ci->prev, list.ci, list.ci->data, list.ci->next);
while (LPrevious(&list, &data, 0))
printf(" - [%p|%p(%d)|%p] - \n", list.ci->prev, list.ci, list.ci->data, list.ci->next);
}
printf("최종으로 남은 노드의 개수는? ( %d )\n", list.count);
return 0;
}
// 함수 정의 존
void ListInit(List* list)
{
// 헤더 생성 및 초기화
list->head = NULL;
// 카운트 초기화
list->count = 0;
// 인덱스 노드를 초기화
list->ci = NULL;
return;
}
void LInsert(List* list, int data)
{
// 새 노드 생성
struct node* new_node = nmm.CreateNodeAuto();
// 새 노드 초기화
new_node->data = data;
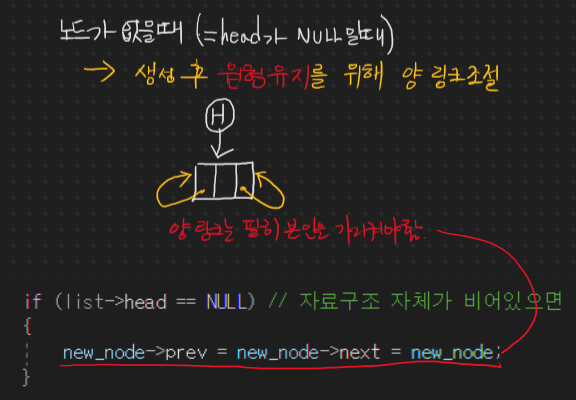
if (list->head == NULL) // 자료구조 자체가 비어있으면
{
new_node->prev = new_node->next = new_node;
}
else
{
// 새 노드의 양 링크를 연결.
new_node->next = list->head; // 1. [새 노드] -> 기존 시작 노드 연결
new_node->prev = list->head->prev; // 2. 기존 끝 노드 <- [새 노드] 연결
// 양쪽 노드의 prev 링크들을 연결.
new_node->next->prev = new_node; // 새 노드 <- [기존 시작 노드] 연결
new_node->prev->next = new_node; // 새 노드 <- [기존 끝 노드] 연결
}
// 헤드와 빈 노드 연결
list->head = new_node;
// 노드 추가 완료 시, 카운트 증가
list->count++;
return;
}
int LFirst(List* list, int* data)
{
// 헤드를 검사한다. 널이면 false 반환, 널이 아니면 진행
if (list->head == NULL)
return false;
// 인덱스를 옮긴다.
list->ci = list->head;
// 데이터 참조하여 값을 변경
*data = list->ci->data;
// true 반환
return true;
}
int LNext(List* list, int* data, int non_exit)
{
// LFirst 가 실행되지 않은 경우는 false
if (list->ci == NULL)
return false;
// 다음 가리키는 것이 헤드가 가리키는 것과 같은지를 확인한다. -> 끝인지를 확인하는 방법 -> 같으면 false 반환
// 원형이기 때문에 검사가 필요한데, non_exit인자는 원점을 지나쳐 원형으로 계속해서 순회하기 위해서 넣음.
if ((non_exit == false) && (list->head == list->ci->next))
return false;
// 인덱스를 옮긴다.
list->ci = list->ci->next;
// 데이터 참조하여 값을 변경
*data = list->ci->data;
// true 반환
return true;
}
int LPrevious(List* list, int* data, int non_exit)
{
// LFirst 가 실행되지 않은 경우는 false
if (list->ci == NULL)
return false;
// 해당 노드의 prev가 가리키는 것이 헤드가 가리키는 것과 같인지를 확인한다 -> 끝인지를 확인하는 방법 -> 같으면 false 반환
if ((non_exit == false) && (list->head == list->ci->prev))
return false;
// 인덱스를 역행으로 옮긴다.
list->ci = list->ci->prev;
// 데이터 참조하여 값을 변경
*data = list->ci->data;
// true 반환
return true;
}
void LRemove(List* list)
{
// 타겟의 링크들이 끊기기 전에 따로 주소 값을 기록한다.
struct node* target = list->ci;
// 삭제할 타겟이 head가 가리키고 있는 노드라면
if (list->head == target)
{
// 삭제할 타겟의 양 링크가 본인을 가리킨다면 삭제할 타겟은 하나!
if (list->head == list->head->next)
list->head = NULL;
else
list->head = target->next; // 헤드를 다음 노드로 옮겨준다.
}
// 타겟의 전 노드의 next 를 타겟의 next로 바꾼다
target->prev->next = target->next;
// 타겟의 다음 노드의 prev 를 타겟의 prev로 바꾼다
target->next->prev = target->prev;
// count를 줄인다.
list->count--;
// 메모리 해체는 NMM 객체가 알아서 해준다.
return;
}