C기반 I/O Multiplexing - 1. Multiprocessing과 Multiplexing 비유
최근, 아니 비교적 최근에 어떤 게임 클라이언트를 활용한 게임 서버를 만드는 프로젝트를 진행했던 적이 있고, 지금도 조금씩 조금씩 하고 있으나, 우선 순위에 밀려 소홀하긴 하지만 진행하고
typingdog.tistory.com
이전 글에서 비유를 통해서 Multiplexing이 뭔지 느껴 보았을 터이다.
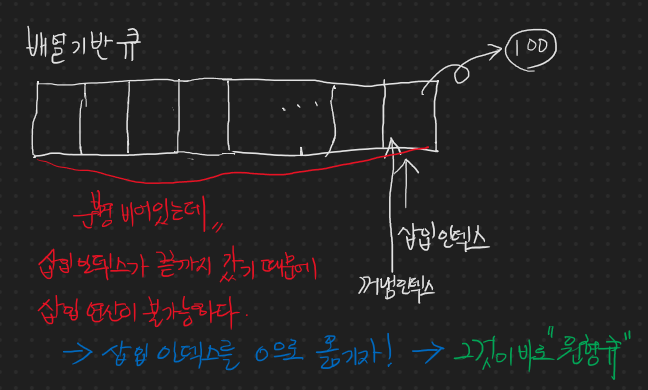
그 멀티플렉싱 기반의 다중 처리 소켓 모델이 있는데, 이 소켓 모델을 이용해서 다중 접속에 대한 처리를 서버 하나로 처리할 것이고, 그 과정을 정리하는 블로깅이다.

이런 상황에서 서버를 어떻게 코딩 해야? 멀티 플렉싱 모델을 적용할 수 있을지를 기록할 것이다. 여기서 우리는 select 라는 함수를 사용하는데 일반 함수를 띡
strtok( ... );
호출하는 것과는 차원이 다르게 알아둬야 할 배경이 많다. 내가 느끼기엔 ㅋㅋ (strtok 함수도 사용하기 까다로웠음)
일단 기본 컨셉을 다루기 전에 앞서, 리눅스 시스템에서의 파일 디스크립터라는 개념을 알아야 한다. 윈도우의 경우에는 핸들이라는 개념으로 사용되는데 거의 비슷한 개념이라고 생각하고 모델을 구현해도 무리가 없다.
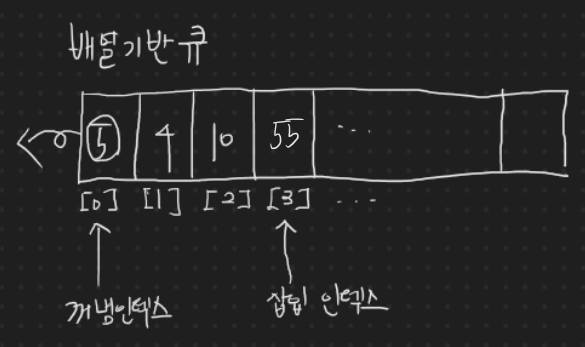
File Descriptor(파일 디스크립터) : 직역해보면 '파일 설명자'이다. 조금만 다듬으면 파일 식별자 라고 생각하면 되는데, 파일을 생성할 때, 해당 파일에 주어지는 번호라고 생각하면 된다. 즉, 그 파일을 간단하게 지목할 수 있는 번호표와 같다. 그런데 리눅스에서는 생성되는 파일 뿐만 아니라, 생성되는 소켓에 대해서도 파일 취급을 하고, 파일 디스크립터를 할당한다. 다음과 같이 말이다.(0과 1과 2는 표준 입출력들에 대해 이미 예약되어 있다. - 순서대로 stdin, stdout, stderr)

근데 이걸 왜 알아야하냐? select 함수는 바로 이 파일 디스크립터를 잘 요리조리 볶아서 다중 접속 처리를 하기 때문이다. 윈도우도 마찬가지다. 파일 디스크립터에서 핸들을 다룬다라는 것 외에는 다를 바가 없다.
그러면 기본 컨셉을 조금 표현해 볼 것이다.
첫 번째, 파일 디스크립터의 등록이다.

그림 내의 글을 읽어보면 되지만, 부가 설명을 넣자면 fd_set 은 구조체 자료형이다.

요런 식으루 생겼고 ㅋㅋ (답없다ㅋㅋ), 비트처럼 동작한다고 생각하면 된다. 생성된 소켓들의 파일 디스크립터들이 배열로 나열되고, 0과 1로 변화의 유무를 표현한다고 생각하면 마음이 편할 것 같다.ㅋㅋ

이러한 배열을 조작하는 매크로 함수가 위위 그림에 나열한 것들이다.
FD_ZERO : 해당 배열을 모두 0으로 초기화.
FD_SET : 해당 파일 디스크립터를 배열에 등록.
FE_CLR : 해당 파일 디스크립터를 배열에서 제거.
FD_ISSET : 해당 파일 디스크립터가 배열에 등록되어 있니?
코드로 확인하겠다 나중에ㅋㅋ
두 번째, 준비는 완료 되었다! Select 함수의 호출이다!!!!

위에는 select 함수의 인자 설명이고, 아래는 호출의 예이다.
__nfds 인자는 select 함수가 검사할 파일 디스크립터의 범위를 묻는 것이다. 범위면 범위지 왜 max + 1 같은 숫자를 입력하는건가?
리눅스에서 파일 디스크립터는 0부터 순차적으로 생성이 된다. 그러니까 제일 마지막에 생성되는 파일 디스크립터가 곧 총 생성된 파일 디스크립터 중 마지막 번호를 가지고 있을 것이고, 거기서 더하기 1을 한 값이 총 갯수가 된다.


파일 디스크립터가 "순차적"으로 값이 증가하는 것이 보장되기 때문에 범위를 지정하는 항목에 끝 번호 + 1 이 올 수 있는거다. 끝 번호 + 1 을 알면 0 ~ 끝 번호가 범위겠거니~ 하면 되니까!
추가 --
아, 맞다! 윈도우 같은 경우는 핸들이 순차적으로 생성되지 않는다! 그래서 fd_set을 다루는 방법이 조금 다르긴 하다 ㅋㅋ 그래서 윈도우에서는 첫 번째 인자를 사용하지 않고 뭐 알아서 범위를 잡아서 계산해주나보다. 다만, 리눅스 소켓 계열과 호환성 때문에 남겨두었다고 한다. 이거 빼먹을 뻔 했음 - 근데 나는 리눅스 계열 소켓만 준비했기 때문에...
--
세 번째, select 함수 호출 이후 변화를 살펴볼 것이다. select 함수 호출 직 후부터 지정한 시간동안 변화가 발생했을 때와 발생하지 않았을 때를 본다.

시간을 지정한다고 했는데 간단하다. 아래 그림 두 장과 설명을 보면 된다.


먼저, 변화가 발생했을 때이다.

두 개 변화했으니 저 변한 녀석들에 대해서만 반복문이든 뭐든 써서 데이터 수신 처리와 그에 맞는 송신 처리를 진행하면 된다!! 참 쉽지 않는가!!!!
저 두 녀석을 찾는 방법은 FD_ISSET 이라는 매크로 함수를 이용하여 찾아낸다. 정확히는
fd_set 배열 내 일어난 변화가 클라이언트1 fd인가?
fd_set 배열 내 일어난 변화가 클라이언트2 fd인가?
라는 질문을 FD_ISSET 과 조건문으로 주구장창 물어보면 된다 ㅋㅋ 그 방법은 코드로 익히는게 빠르다.
그럼 변화가 발생하지 않을 때에는?

그냥 뭐 처리할게 없다. 왜냐? 뭔가 송신한 클라이언트가 없으니 변화가 안 일어났기 때문이다 ㅋㅋ
자, 이렇게 하면 과정들을 대충 훑어보았다. 개념만 대충 잡히면 된다. 나머지는 코드로 확실히 보면 되니까 말이다. 함수들이나 매개변수의 정확한 용어나 쓰임을 분석 단위로 보려면 찾아보면 된다. 그거 올려놓으면 나중에 까먹어서 다시 볼 때 하나도 머리에 안 들어오고 안 읽힌다
다음 시간에는 코드다. 정리하기 너무 힘들다 진짜 ㅋ
'프로그래밍응용 > Socket' 카테고리의 다른 글
| C기반 I/O Multiplexing - 6. Select와 Epoll의 차이점과 Epoll 컨셉 (0) | 2021.01.18 |
|---|---|
| C기반 I/O Multiplexing - 5. Select 모델의 단점 (0) | 2021.01.18 |
| C기반 I/O Multiplexing - 4. Level Trigger와 Edge Trigger (0) | 2021.01.17 |
| C기반 I/O Multiplexing - 3. Select 함수 활용 코드 (0) | 2021.01.17 |
| C기반 I/O Multiplexing - 1. Multiprocessing과 Multiplexing 비유 (0) | 2021.01.15 |