C기반 I/O Multiprocessing - 8. 드디어 올리는 멀티 프로세싱
진짜 다 까먹어서 다시 예제 쳐보고 다시 올린다... 정말 미리미리 올리고 자주자주 봐야합니다.. 포스팅 순서가 사실 멀티 프로세싱이 먼저이지만, 게임 서버 개발에 사용한 것은 멀티 플렉싱
typingdog.tistory.com
C기반 I/O Multiprocessing - 9. 멀티 프로세싱에서 좀비 문제
C기반 I/O Multiprocessing - 8. 드디어 올리는 멀티 프로세싱 진짜 다 까먹어서 다시 예제 쳐보고 다시 올린다... 정말 미리미리 올리고 자주자주 봐야합니다.. 포스팅 순서가 사실 멀티 프로세싱이 먼
typingdog.tistory.com
C기반 I/O Multiprocessing - 10. 멀티 프로세싱 기반 서버
C기반 I/O Multiprocessing - 8. 드디어 올리는 멀티 프로세싱 진짜 다 까먹어서 다시 예제 쳐보고 다시 올린다... 정말 미리미리 올리고 자주자주 봐야합니다.. 포스팅 순서가 사실 멀티 프로세싱이 먼
typingdog.tistory.com
위 링크들에서 볼 수 있듯이 멀티 프로세싱의 주요 맥락을 확인하고, 포스팅하여 기록해보았다. 그런데 말입니다, 부모 프로세스와 자식 프로세스들 간에 통신이 필요한 경우는 어떻게 해야할까?
아니, 사실 프로세스들 간에 통신을 안 하는게 최고라고 나는 생각하지만 또, 그게 아닐 수 있으니 프로세스들 간의 통신 방법에 대해서 공부하고 넘어가는게 났겠다 싶어서 전에 공부를 해 보았다.
일단, 프로세스들 간의 통신에 대해서 정리하기 전에 멀티 프로세스에 대한 정리를 한번 할 필요가 있다. 왜냐하면 이전 포스팅에서는 코드 구현 관점에서만 설명이 되어서 프로세스에 대한 충분한 설명이 이루어지지 않았다.
멀티 프로세스 개념 간단 정리

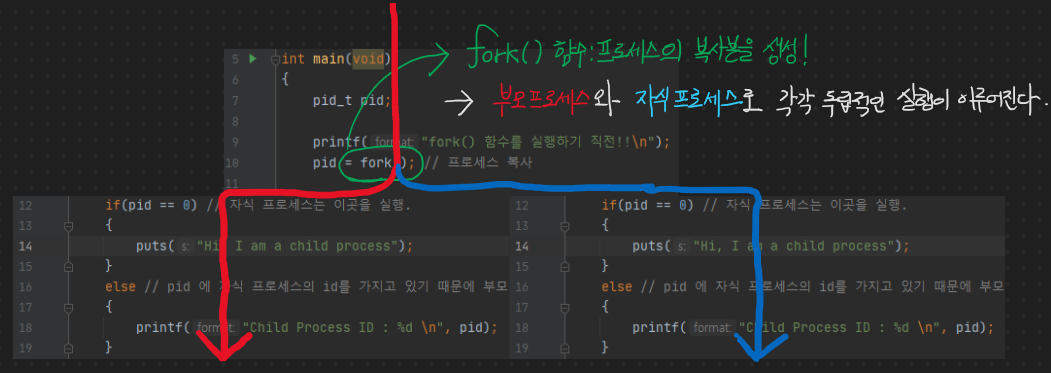
1. fork 함수를 통해서 프로세스가 복사되는데, 이 때, 복사라는 과정은 사실 새로운 프로세스의 생성 과정을 거친다.( PCB, Process Controll Block 이 함께 생성되어 생성된 프로세스에 대한 정보들을 저장하는 자료구조 블록이며, 컨텍스트 스위칭 때 이 정보를 활용한다)
2. fork 함수를 통해서 프로세스가 복사 시에는 부모 프로세스의 스택, 데이터, 힙 영역이 모두 복사되어 부모와 자식은 완전히 별개의 메모리 공간을 갖으며 내용 또한 그대로 복사된다.
자, 1번과 2번의 특징으로 인해서 프로세스 간에는 아무리 부모와 자식 사이의 관계라고 하더라도 서로 독립적인 메모리 공간을 가지고 있기 때문에 통신하기가 힘들다. 그래서 프로세스 간의 대화 방법으로 나온 것이 IPC이다.
IPC란?
IPC란 Inter Process Communication의 줄임말로 프로세스 간의 통신 방법을 의미한다.
내가 공부한 프로세스 간 통신 방법은 다음 그림으로 설명할 것이다.

이게 바로 파이프를 이용한 프로세스 간의 통신을 간략하게 그림으로 그려본 것이다.

파이프의 생성은 위와 같은 함수로 진행된다. 운영체제에서 생성되는 공간이기 때문에 프로세스들과는 무관한 독립된 공간이고, fork 시 코드에 포함이 되어 있더라도 복제되는 메모리 공간이 아니다.
예제 코드 및 실행 결과
어떻게 데이터를 주고 받는지 부모가 자식에게, 자식이 부모에게 데이터를 주고 받는 경우를 예제로 확인해 볼 것이다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
#include <stdio.h>
#include <unistd.h>
#define BUFSIZE 40
int main(void)
{
int fds[2];
pid_t pid;
char from_c_to_p[] = "우리 부모님아!";
char from_p_to_c[] = "내 자식아!";
char buf[BUFSIZE];
pipe(fds);
// 파이프 생성 -> 파이프는 fork 에 의해 복사되지 않고, 운영체제에 의해 생성되는 메모리 공간이다.
// 이 파이프를 이용하여 부모 프로세스와 자식 프로세스가 데이터를 교환할 수 있으며, 이런 통신 방법을 IPC 라고 한다.
// 인자로 전달되는 fds에 데이터 입력과 출력에 해당하는 파일 디스크립터가 저장이 된다.
// fds[0]에는 출력을 위한 파일 디스크립터가 저장되고, 프로세스는 이 디스크립터를 통해서 값을 가져온다.
// fds[1]에는 입력을 위한 파일 디스크립터가 저장되고, 프로세스는 이 디스크립터를 통해서 값을 입력한다.
pid = fork();
if(pid == 0)
{
write(fds[1], from_c_to_p, sizeof(from_c_to_p));
sleep(2);
read(fds[0], buf, BUFSIZE);
printf("부모가 자식에게 보내온 메시지 : [%s]\n", buf);
}
else
{
read(fds[0], buf, BUFSIZE);
printf("자식이 부모에게 보내온 메시지 : [%s]\n", buf);
write(fds[1], from_p_to_c, sizeof(from_p_to_c));
sleep(5);
}
return 0;
}
|
cs |
29번 라인과 40번 라인의 sleep 함수에 대한 설명이 필요한 것 같다ㅋㅋㅋ 먼저, 29번 라인은 자식 프로세스에서 실행되는 영역에 sleep 함수를 넣었다. 왜 넣었을까?
먼저, 29번 라인에 sleep 함수가 없다고 생각하고, 28번 라인에서 입력 파일 디스크립터를 이용하여 값을 파이프에 집어 넣으 후, 31번 라인에서 바로 출력 파일 디스크립터를 이용하여 값을 파이프에서 빼내면 자식 프로세스 본인이 방금 넣은 값이 나올 확률이 높다. 36번 라인에서 부모 프로세스도 출력 파일 디스크립터를 이용하여 파이프에서 값을 빼내고 있으므로 자식 프로세스에서의 31번 라인과 부모 프로세스에서의 36번 라인 중 어떤 라인을 먼저 읽느냐에 따라 달린 것이기 때문이다. 아래와 같이.

그러나 29번 라인에서 sleep 함수를 실행함으로써 부모 프로세스가 먼저 값을 가져갈 수 있도록 여유를 두면 정상적으로 실행된다 다음처럼.
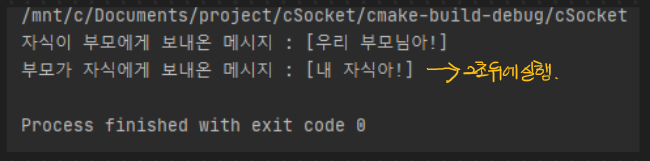
그리고 40번 라인의 부모 프로세스 실행 영역에서 5초 정도의 여유를 준 이유는 부모 프로세스가 종료하면 자식 프로세스도 함께 죽기 때문에 자식 프로세스가 충분히 부모가 전송한 데이터를 꺼낼 시간을 기다리기 위해서 5초의 여유를 준 것이다.
그런데 이렇게 데이터를 넣고, 꺼내는 타임을 sleep 함수를 통해 실행 흐름까지 막아서 조정해가면서 행하는게 이게 프로그램으로서 말이나 된단 말인가?
아니, 그러면 애초에 부모용 pipe, 자식용 pipe 이렇게 구분해서
자식은 자식 파이프의 입력 디스크립터와, 부모 파이프의 출력 디스크립트만 사용하고,
부모는 부모 파이프의 입력 디스크립터와, 자식 파이프의 출력 디스크립트만 사용하면 된다.
다음 소스 코드와 실행 결과를 통해 볼 수 있다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
#include <stdio.h>
#include <unistd.h>
#define BUFSIZE 40
int main(void)
{
int fds1[2], fds2[2]; // 순서대로 자식용 파이프, 부모용 파이프
pid_t pid;
char from_c_to_p[] = "우리 부모님아!";
char from_p_to_c[] = "내 자식아!";
char buf[BUFSIZE];
pipe(fds1);
pipe(fds2);
pid = fork();
if(pid == 0)
{
write(fds1[1], from_c_to_p, sizeof(from_c_to_p));
read(fds2[0], buf, BUFSIZE);
printf("부모가 자식에게 보내온 메시지 : [%s]\n", buf);
}
else
{
read(fds1[0], buf, BUFSIZE);
printf("자식이 부모에게 보내온 메시지 : [%s]\n", buf);
write(fds2[1], from_p_to_c, sizeof(from_p_to_c));
sleep(5);
}
return 0;
}
|
cs |


위와 같은 이런 모양새인 것이다.
이로써 IPC 까지 프로세스에 대한 내용은 모두 마친다.
'프로그래밍응용 > Socket' 카테고리의 다른 글
| C기반 I/O Multithreading - 13. 쓰레드의 생성과 소멸까지 (0) | 2021.02.03 |
|---|---|
| C기반 I/O Multithreading - 12. 멀티 프로세싱? 멀티 쓰레딩? (0) | 2021.02.03 |
| C기반 I/O Multiprocessing - 10. 멀티 프로세싱 기반 서버 (0) | 2021.02.01 |
| C기반 I/O Multiprocessing - 9. 멀티 프로세싱에서 좀비 문제 (0) | 2021.02.01 |
| C기반 I/O Multiprocessing - 8. 드디어 올리는 멀티 프로세싱 (0) | 2021.02.01 |